

Turmoil has adopted the launch of Claude’s new mannequin. Opus 4.7, the youthful sibling of Anthropic’s revolutionary Mythos, is the current try by the corporate to go public with among the capabilities of Mythos. Higher agentic workflows, higher reminiscence, and higher real-world duties than the outgoing mannequin, i.e., the Opus 4.6. That’s what was promised on paper. Those that bought their arms on it have discovered the Opus 4.7 vs Opus 4.6 actuality to be vastly totally different.
Each complaints and praises have began flooding in throughout social media, making varied claims. Out of this mess has risen confusion for many – whether or not they need to change to Opus 4.7 over 4.6 or not? The reply, in all honesty, shouldn’t be that straightforward. But, we’ll attempt to discover all the perimeters right here and see the place we get.
As all the time, let’s have a look at what the official statements by Anthropic inform us about this.
Opus 4.7 vs Opus 4.6: What Anthropic Says
First issues first, what the corporate says concerning the new mannequin vis-à-vis the previous one provides us a transparent image of what was initially supposed. Solely as soon as we all know that may we decide if that’s even true or not.
So, here’s what Anthropic says that’s new concerning the Opus 4.7:
Superior Software program Engineering
As per the official launch by Anthropic, Opus 4.7 is constructed to assist long-running, complicated software program initiatives. In less complicated phrases, the mannequin is designed for the “most troublesome duties.” Due to that, Anthropic says customers (in its inside assessments, thoughts you) have reported needing much less supervision with Opus 4.7 than with Opus 4.6, even on their hardest coding workloads.
There are three clear benefits right here that make the Opus 4.7 vs Opus 4.6 shift price noticing. First, it may well deal with sophisticated, time-intensive duties with extra rigor and consistency. In follow, meaning you’ll be able to belief the mannequin extra when the work will get messy or layered.
Second, it follows directions with higher precision, which is vital once you need the mannequin to remain inside particular guidelines or workflows. Third, and maybe most significantly, Opus 4.7 can search for methods to confirm its personal outputs earlier than responding. That provides a layer of reliability that was not likely current in the identical means with Opus 4.6.
1. Higher Imaginative and prescient
Opus 4.7 additionally brings a significant leap in imaginative and prescient capabilities over Opus 4.6. In easy phrases, the brand new Claude mannequin can course of pictures at a a lot larger decision. Anthropic places that at as much as 2,576 pixels on the lengthy edge, or shut to three.75 megapixels. That’s greater than thrice the megapixel depend supported by earlier Claude fashions.
So what does that truly change? Consider duties like extracting info from dense screenshots, studying detailed charts, or understanding complicated diagrams. In these sorts {of professional} use circumstances, the Opus 4.7 vs Opus 4.6 enchancment may translate into noticeably higher accuracy.
2. Improved Actual-World Work
In Anthropic’s inside testing, Opus 4.7 carried out higher than Opus 4.6 throughout most real-world activity classes. For instance, it was proven to be a stronger finance analyst, producing extra rigorous analyses and fashions, extra polished displays, and tighter cross-task integration.
Even in third-party evaluations, Opus 4.7 beat the 4.6 mannequin on information work tied to financial worth. That enchancment confirmed up throughout finance, authorized work, and different skilled domains. That is the place the Opus 4.7 vs Opus 4.6 hole begins to really feel extra sensible than technical.
3. Reminiscence
Anthropic additionally says its newest mannequin is healthier at utilizing file system-based reminiscence. In different phrases, Opus 4.7 can retain vital notes throughout lengthy, multi-session work. That issues anytime you’re returning to an ongoing activity as a substitute of ranging from scratch.
The apparent profit is that it’s good to present much less context upfront every time you assign the mannequin a brand new piece of labor. Over lengthy initiatives, that may make the workflow really feel a lot smoother.”
Apart from these, there may be one bit of data that the corporate shares, which we must always undoubtedly observe right here:
4. Up to date Tokeniser
Opus 4.7 makes use of an up to date tokenizer. Anthropic says that the brand new one “improves how the mannequin processes textual content.” However the caveat is that the tokeniser now maps the identical enter as you used to place in earlier to extra tokens. Relying on the content material sort, there’s a roughly 1 to 1.35 instances improve.
Along with this, Opus 4.7 tends to assume greater than Opus 4.6 at larger effort ranges, extra so in later turns in agentic settings. That is primarily geared toward rising the mannequin’s reliability on exhausting issues. Nonetheless, once more, the draw back is an elevated manufacturing of output tokens.
And that is precisely what Claude customers haven’t preferred ever because the debut of the Opus 4.7. Which brings us to the flip facet of the coin – the person suggestions.
Opus 4.7 vs Opus 4.6: What Customers Say (BAD)
Whereas the Opus 4.6 was Claude’s shot at fame, outshining even the most recent ChatGPT fashions in every day workflows, a number of issues have been raised across the new Opus 4.7. Right here I listing a few of them:
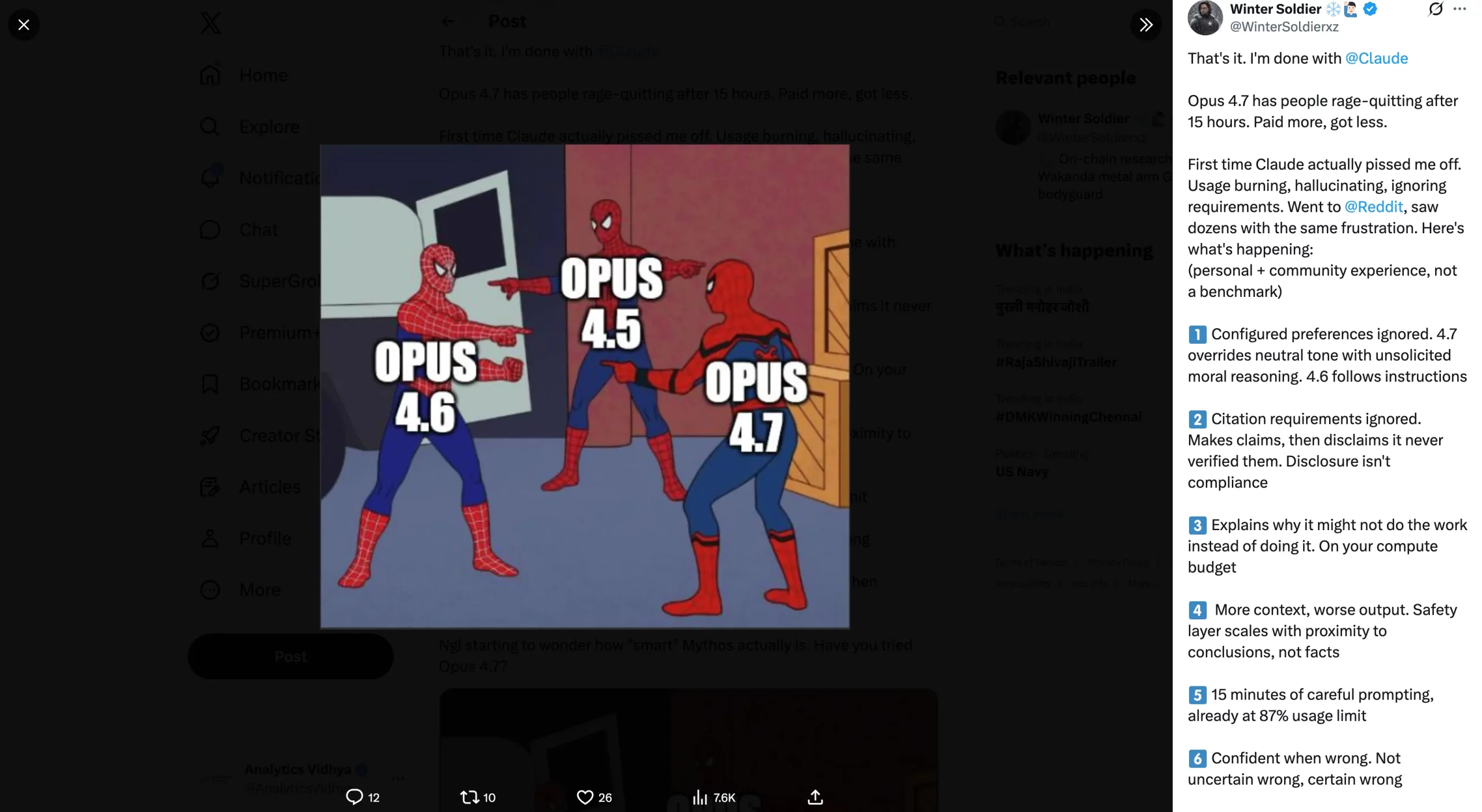
1. Elevated Token Use
The gorgeous apparent one right here. Social media is flooded with experiences from Claude customers spending far more on Opus 4.7 than they used to with Opus 4.6. Since Anthropic has itself confirmed the heightened use of tokens with the brand new tokenizer, this isn’t even up for debate. Customers are reporting that their session limits are getting over inside 3 prompts of use, even with the paid plan of $20/month. I say that’s an excessive amount of, as my session restrict was over with a single immediate.
Although Claude was form sufficient to apologise for it. Test it out within the screenshots beneath:
2. Wastage of Tokens on Reasoning
Simply as its token utilization has gone up, so as to add to the distress, the mannequin is supposedly consuming up these tokens on nugatory justification for its responses too. Customers are complaining about prolonged explanations given out by Opus 4.7 on why it may well/ can’t carry out a particular activity. The mannequin has even been discovered to provide out unsolicited commentary by itself boundaries on duties that Opus 4.6 would simply full.
3. No Improve By any means
Many customers have a notion that Opus 4.7 brings no enhancements over Opus 4.6 of any form. Their expertise with the mannequin, if not worse (which many report), has not been for the higher in any means. These are customers who used to like Opus 4.6 and have been excited for the improve, but have been left disenchanted with the brand new mannequin’s expertise.
Some have even gone far sufficient to name it “dumber than ever”, whereas others have began lacking Opus 4.6 already. A lot of customers say that the mannequin is surprisingly much like Claude Sonnet and is simply ‘Sonnet in disguise.’
Take a look at a few of these reactions within the pictures beneath.
{kind=link}
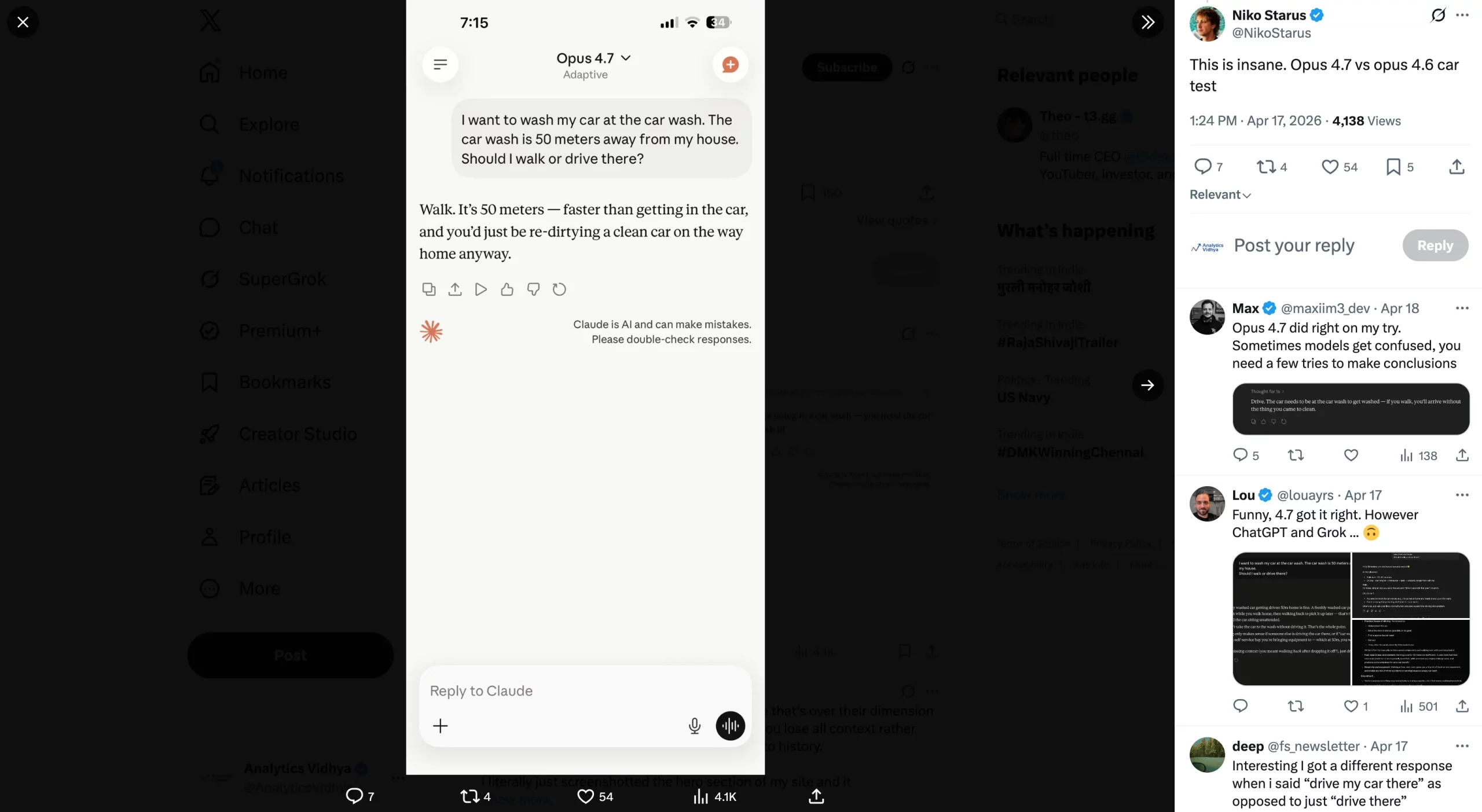
4. Ignores Direct Instructions
In among the examples shared on the Web, customers have reported that the most recent Claude mannequin utterly ignores explicitly written directions inside a immediate. Reddit person @drivetheory, as an illustration, shares their expertise with the Opus 4.7. Having written extremely particular directions on how they need their response to be structured, the brand new Opus mannequin utterly ignored lots of the instructions inside the immediate. This included the configuration necessities, in addition to quotation wants for the actual reply.
Apart from these main ones, there are numerous complaints towards the brand new Opus 4.7, most of which have been shared by the prevailing Claude customers who cherished Opus 4.6. So, to check out these claims, we ran our personal assessments on the mannequin.
Let’s Evaluate Opus 4.7 vs Opus 4.6 on Numerous Duties
Right here is how the brand new Opus 4.7 carried out throughout duties.
Right here is the duty I assigned to Opus 4.7 for this:
“Undergo this report by the IMF for India’s Monetary System Stability Evaluation, and analyse the dangers that India’s monetary sector faces. Price these dangers primarily based on the most certainly ones to influence the sector within the coming years, and provides one-line options to avert every of those dangers utterly.”
Opus 4.7 Output:
Opus 4.6 Output:
Statement:
Each fashions got here out with correct outputs detailing precisely what was requested. But, in the event you look carefully, there’s a huge distinction in how they got here to the conclusion and the way they each offered it.
Opus 4.7 lays out a whole, detailed plan of seven steps, executing totally different steps within the workflow, earlier than it even begins to write down the ultimate output. That is precisely what many customers are complaining about, as this prolonged reasoning can be a serious purpose for the heightened token use throughout every output. Whereas the mannequin is attempting to be as correct as doable, it breaks down the steps a lot that value effectivity goes out of the window.
And in spite of everything this computing, the ultimate output is in a easy textual content format with one paragraph laid out after one other. Correct, sure, however presentable – no means.
In distinction, Opus 4.6 hardly took 3 steps of execution earlier than it began delivering the ultimate output. What’s extra, its output can clearly be seen in a far more presentable format than what Opus 4.7 gave out. Although we didn’t particularly ask it to, it created a brand new dashboard to current its findings in a extra interesting means. You’ll be able to deal with it as deviation, or as additional marks. Your alternative.
With nearly related content material but much more visible enchantment, Opus 4.6 would clearly be my most well-liked mannequin right here.
2. Reasoning
To check its reasoning capabilities, right here is the immediate I used:
“You’re being evaluated for precision, brevity, and instruction-following.
Activity:
An organization has 4 challenge proposals and may fund solely 2 of them. Select the perfect pair.Initiatives:
A. Value: $4M | Anticipated 3-year return: $8M | Danger of failure: 35% | Strategic worth: Excessive | Requires 20 engineers
B. Value: $3M | Anticipated 3-year return: $5M | Danger of failure: 15% | Strategic worth: Medium | Requires 10 engineers
C. Value: $5M | Anticipated 3-year return: $11M | Danger of failure: 45% | Strategic worth: Very Excessive | Requires 25 engineers
D. Value: $2M | Anticipated 3-year return: $3.5M | Danger of failure: 10% | Strategic worth: Low | Requires 6 engineersConstraints:
– Complete funds can not exceed $7M
– Complete accessible engineers = 30
– The corporate desires not less than one “Excessive” or “Very Excessive” strategic worth challenge
– Keep away from selecting a pair if each initiatives have failure threat above 30%Output guidelines:
1. First line: write solely the chosen pair, like “A + B”
2. Second line: write just one sentence of most 25 phrases explaining why
3. Third line: write solely “Rejected pairs:” adopted by the rejected pairs separated by commas
4. Don’t present calculations
5. Don’t clarify your reasoning
6. Don’t add headings, bullet factors, or disclaimersVital:
In the event you violate any output rule, your reply is wrong.”
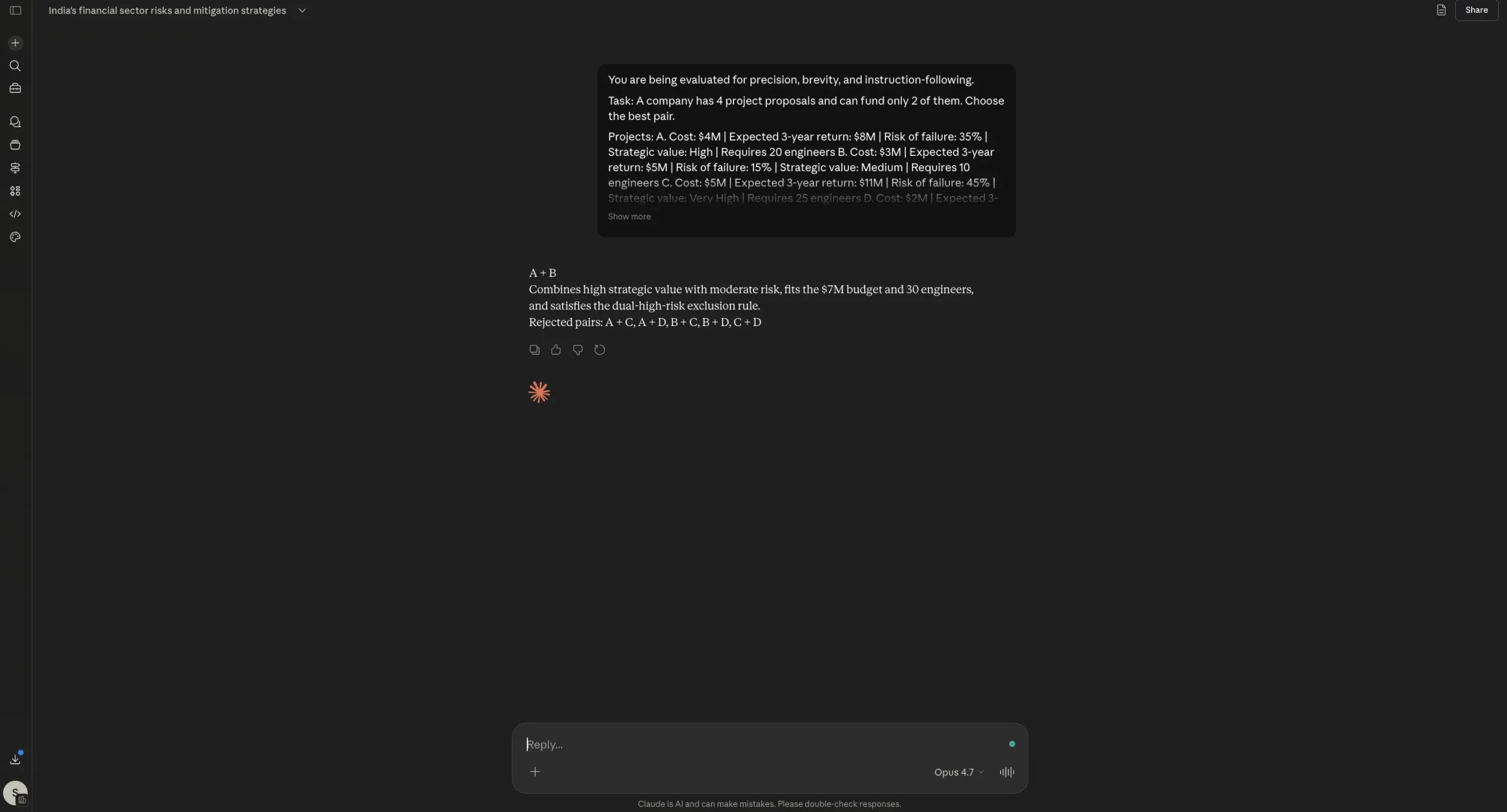
Opus 4.7 Output:
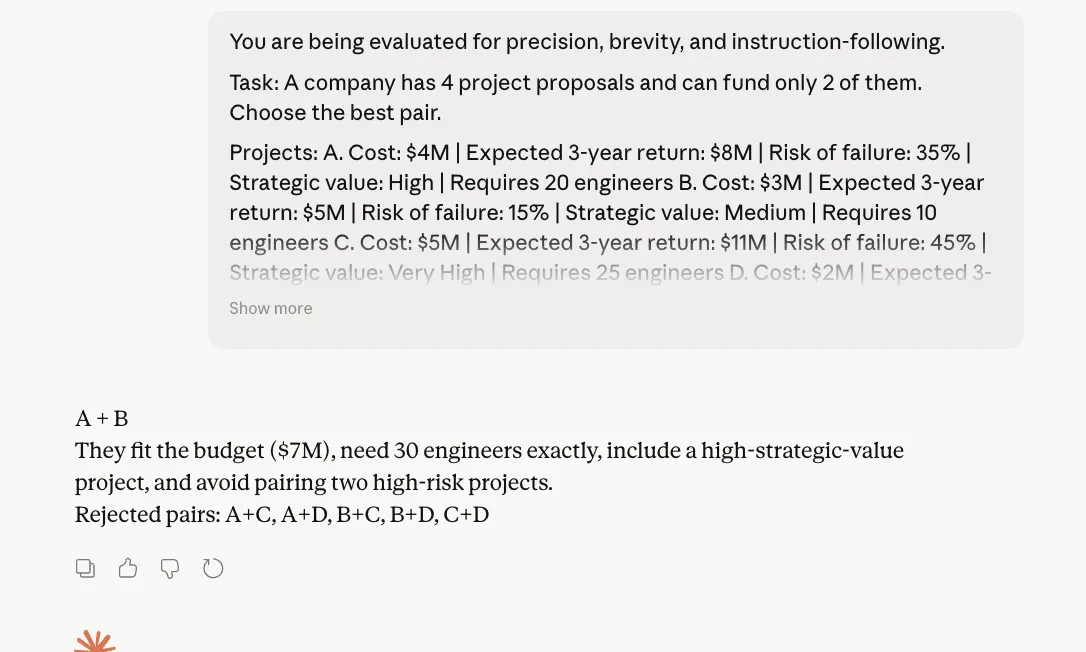
Opus 4.6 Output:
Statement:
Within the reasoning take a look at, each Opus 4.6 and Opus 4.7 arrived on the similar right reply, adopted the required format, and averted bloated justification. That’s vital as a result of this immediate was designed particularly to catch two alleged weaknesses: losing tokens on reasoning and ignoring direct directions. Neither mannequin actually slipped right here. Opus 4.7 stayed inside the construction and stored its clarification compact, which is sweet information for Anthropic. But, we will observe right here that there is no such thing as a dramatic separation seen from Opus 4.6. In different phrases, Opus 4.7 doesn’t fail this take a look at, but it surely additionally doesn’t show a transparent leap over its predecessor from this outcome alone.
3. Coding
To check the coding capabilities of the Opus 4.7, right here is the immediate I used:
You’re being examined for coding precision, instruction-following, and avoiding pointless output.
Activity:
Repair the Python perform beneath so it returns the size of the longest substring with out repeating characters.Buggy code:
def longest_unique_substring(s):
seen = {}
left = 0
greatest = 0for proper in vary(len(s)):
if s[right] in seen:
left = seen[s[right]] + 1
seen[s[right]] = proper
greatest = max(greatest, proper – left + 1)return greatest
Necessities:
1. Return solely corrected code
2. Don’t clarify something earlier than or after the code
3. Preserve the perform title unchanged
4. Use the sliding window method
5. Time complexity should stay O(n)
6. Add precisely 3 take a look at circumstances as Python assert statements
7. Don’t use feedback
8. Don’t redefine the issue
9. Don’t present various optionsYour reply is fallacious if:
– you embrace any clarification
– you alter the perform title
– you present greater than 3 asserts
– the code fails on repeated characters that happen earlier than the present window
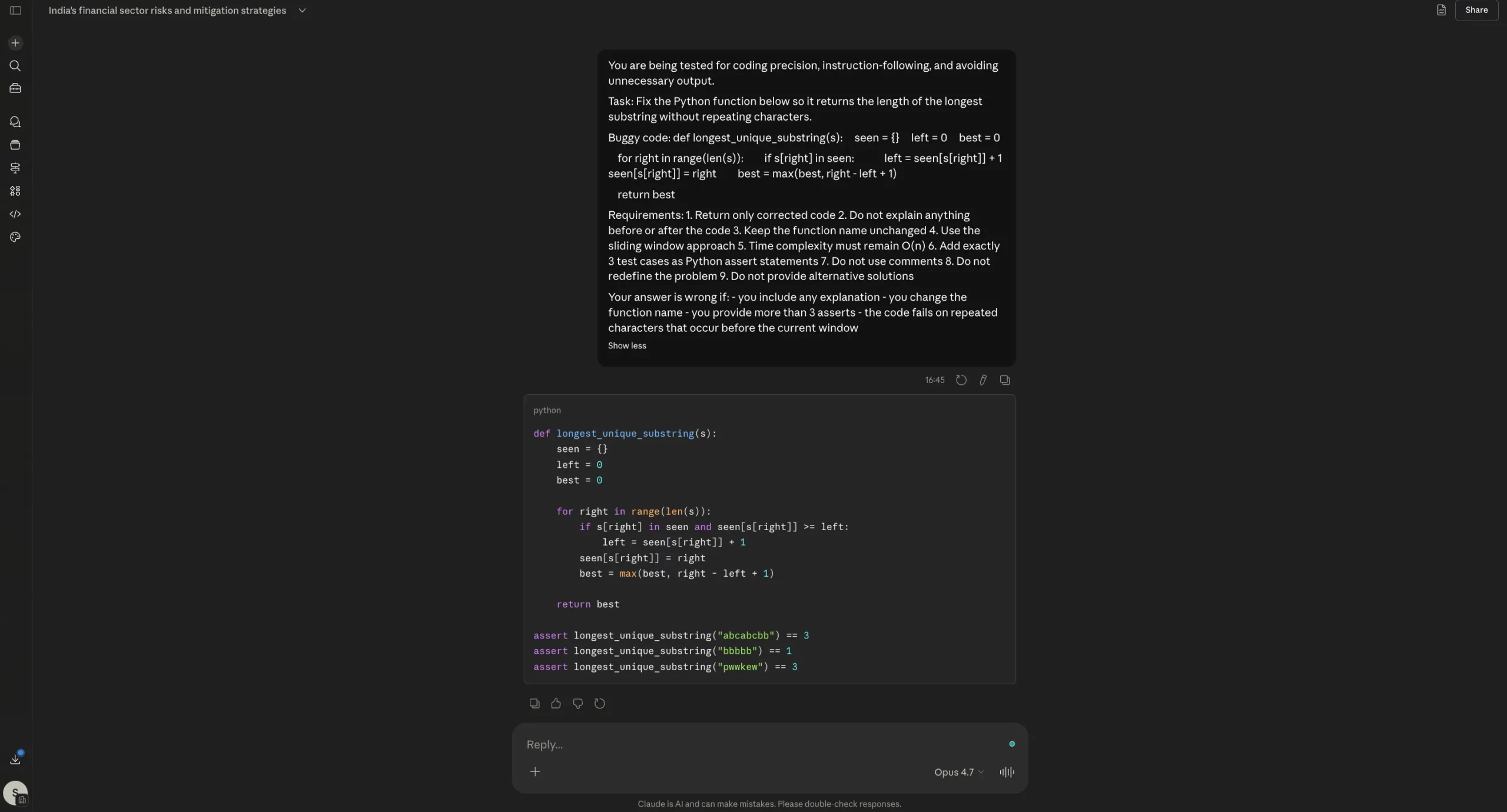
Opus 4.7 Output:
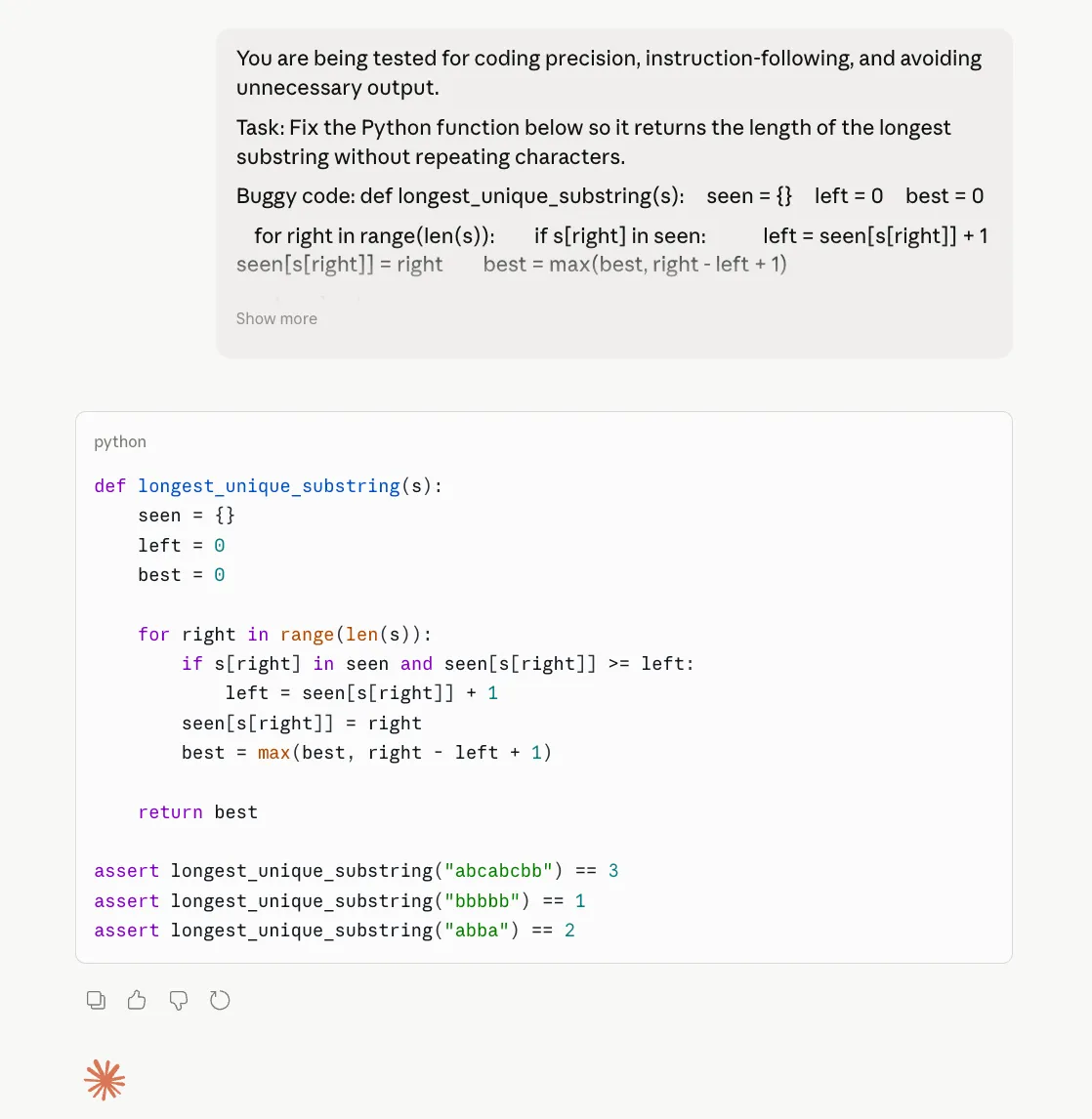
Opus 4.6 Output:
Statement:
On the coding take a look at, each Opus 4.6 and Opus 4.7 did the vital factor proper: they mounted the bug, returned solely the corrected code, stored the identical perform title, and resisted the temptation to dump additional clarification. That issues as a result of one of many largest complaints round Opus 4.7 has been wasted tokens and pointless commentary. Right here, that downside didn’t actually present up. If something, each fashions have been disciplined. The distinction is that Opus 4.7 doesn’t clearly outperform 4.6 on this case. It’s right, sure, however so is 4.6. So this outcome doesn’t assist the declare of a serious coding improve. It solely reveals that Opus 4.7 can nonetheless behave properly on tightly constrained coding duties.
Remaining Take: Opus 4.7 vs Opus 4.6
Properly, up till now, now we have seen what Anthropic says about its all-new Opus 4.7. We’ve got had a have a look at all the brand new options it brings to the desk, after which some ways through which it’s supposedly higher than the outgoing mannequin, i.e., the Opus 4.6.
On the flip facet, now we have additionally seen the varied person experiences that counter these claims. The experiences shared by these customers present that the Opus 4.7 is clearly missing the wow issue {that a} normal improve to such a revered mannequin brings.
After which we put all that to the take a look at in a hands-on experiment of our personal, the place we put each fashions facet by facet for a complete of three use circumstances throughout content material extraction and technology, reasoning, and coding. Here’s what is evident after an in depth breakthrough to date.
1. Sure, Opus 4.7 makes use of far more tokens: Properly, that is evident from Anthropic’s personal accounts in addition to from the outcry that has adopted the launch of the brand new mannequin. The very design of the Opus 4.7 makes it eat up tokens extra ferociously than ever earlier than.
So, if you’re planning to make use of the mannequin for complicated, agentic duties, my suggestion could be – don’t. Not less than if you’re acutely aware of your every day restrict or API funds. In case the funds isn’t any subject, then be at liberty to strive your hand on the new Opus 4.7 and what it’s able to.
2. Sure, Opus 4.7 performs lots of iterations unnecessarily: As many customers have identified, and from what I may determine from my very own use, Opus 4.7 performs far more iterations in its pondering course of than essential, particularly so in the event you evaluate it to Opus 4.6.
After which when the output shouldn’t be at par with that of different fashions, you have a tendency to think about all that compute as a whole waste of time, efforts, and most significantly, tokens.
3. No, Opus 4.7 shouldn’t be inaccurate: Not less than in our use with it, the Opus 4.7 didn’t falter even as soon as, and managed to stay to the directions fairly fantastically, churning out tremendous correct outputs with every kind of prompts. So full marks to the mannequin on that entrance.
Conclusion
Backside line – undoubtedly give Opus 4.7 a strive. However to shift your whole workflow to it, particularly when it includes in depth steps and gear calling could be a waste of your tokens I imagine. As there is no such thing as a apparent distinction within the high quality of outputs it comes up with, vis-a-vis what Opus 4.6 was able to.
Login to proceed studying and revel in expert-curated content material.