

{kind=link}
Amazon Redshift Serverless removes infrastructure administration and guide scaling necessities from knowledge warehousing operations. Amazon Redshift Serverless queue-based question useful resource administration, helps you defend vital workloads and management prices by isolating queries into devoted queues with automated guidelines that forestall runaway queries from impacting different customers. You’ll be able to create devoted question queues with personalized monitoring guidelines for various workloads, offering granular management over useful resource utilization. Queues allow you to outline metrics-based predicates and automatic responses, similar to robotically aborting queries that exceed closing dates or eat extreme assets.
Completely different analytical workloads have distinct necessities. Advertising and marketing dashboards want constant, quick response occasions. Knowledge science workloads may run advanced, resource-intensive queries. Extract, rework, and cargo (ETL) processes may execute prolonged transformations throughout off-hours.
As organizations scale analytics utilization throughout extra customers, groups, and workloads, making certain constant efficiency and price management turns into more and more difficult in a shared setting. A single poorly optimized question can eat disproportionate assets, degrading efficiency for business-critical dashboards, ETL jobs, and govt reporting. With Amazon Redshift Serverless queue-based Question Monitoring Guidelines (QMR), directors can outline workload-aware thresholds and automatic actions on the queue degree—a big enchancment over earlier workgroup-level monitoring. You’ll be able to create devoted queues for distinct workloads similar to BI reporting, advert hoc evaluation, or knowledge engineering, then apply queue-specific guidelines to robotically abort, log, or prohibit queries that exceed execution-time or resource-consumption limits. By isolating workloads and implementing focused controls, this strategy protects mission-critical queries, improves efficiency predictability, and prevents useful resource monopolization—all whereas sustaining the pliability of a serverless expertise.
On this put up, we focus on how one can implement your workloads with question queues in Redshift Serverless.
Queue-based vs. workgroup-level monitoring
Earlier than question queues, Redshift Serverless provided question monitoring guidelines (QMRs) solely on the workgroup degree. This meant the queries, no matter goal or consumer, had been topic to the identical monitoring guidelines.
Queue-based monitoring represents a big development:
- Granular management – You’ll be able to create devoted queues for various workload varieties
- Position-based task – You’ll be able to direct queries to particular queues based mostly on consumer roles and question teams
- Unbiased operation – Every queue maintains its personal monitoring guidelines
Resolution overview
Within the following sections, we look at how a typical group may implement question queues in Redshift Serverless.
Structure Parts
Workgroup Configuration
- The foundational unit the place question queues are outlined
- Incorporates the queue definitions, consumer position mappings, and monitoring guidelines
Queue Construction
- A number of impartial queues working inside a single workgroup
- Every queue has its personal useful resource allocation parameters and monitoring guidelines
Person/Position Mapping
- Directs queries to applicable queues based mostly on:
- Person roles (e.g., analyst, etl_role, admin)
- Question teams (e.g., reporting, group_etl_inbound)
- Question group wildcards for versatile matching
Question Monitoring Guidelines (QMRs)
- Outline thresholds for metrics like execution time and useful resource utilization
- Specify automated actions (abort, log) when thresholds are exceeded
Stipulations
To implement question queues in Amazon Redshift Serverless, you could have the next stipulations:
Redshift Serverless setting:
- Energetic Amazon Redshift Serverless workgroup
- Related namespace
Entry necessities:
- AWS Administration Console entry with Redshift Serverless permissions
- AWS CLI entry (non-compulsory for command-line implementation)
- Administrative database credentials on your workgroup
Required permissions:
- IAM permissions for Redshift Serverless operations (CreateWorkgroup, UpdateWorkgroup)
- Potential to create and handle database customers and roles
Establish workload varieties
Start by categorizing your workloads. Widespread patterns embrace:
- Interactive analytics – Dashboards and reviews requiring quick response occasions
- Knowledge science – Advanced, resource-intensive exploratory evaluation
- ETL/ELT – Batch processing with longer runtimes
- Administrative – Upkeep operations requiring particular privileges
Outline queue configuration
For every workload kind, outline applicable parameters and guidelines. For a sensible instance, let’s assume we wish to implement three queues:
- Dashboard queue – Utilized by analyst and viewer consumer roles, with a strict runtime restrict set to cease queries longer than 60 seconds
- ETL queue – Utilized by etl_role consumer roles, with a restrict of 100,000 blocks on disk spilling (
query_temp_blocks_to_disk) to regulate useful resource utilization throughout knowledge processing operations - Admin queue – Utilized by admin consumer roles, and not using a question monitoring restrict enforced
To implement this utilizing the AWS Administration Console, full the next steps:
- On the Redshift Serverless console, go to your workgroup.
- On the Limits tab, underneath Question queues, select Allow queues.
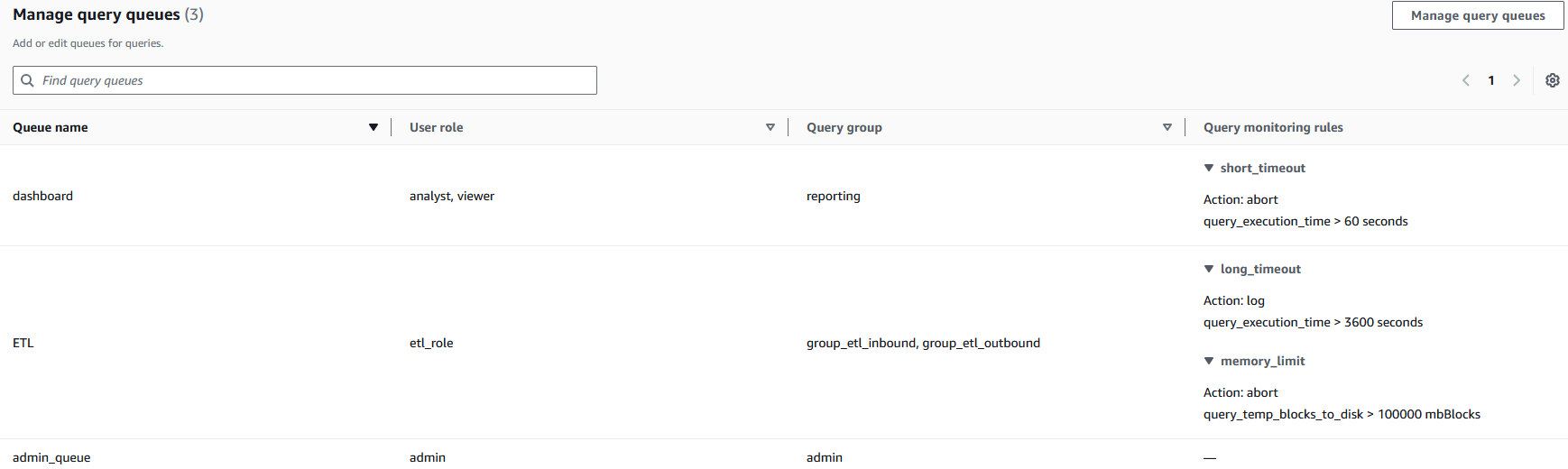
- Configure every queue with applicable parameters, as proven within the following screenshot.
Every queue (dashboard, ETL, admin_queue) is mapped to particular consumer roles and question teams, creating clear boundaries between question guidelines. The question monitoring guidelines implement automated useful resource governance—for instance, the dashboard queue robotically stops queries exceeding 60 seconds (short_timeout) whereas permitting ETL processes longer runtimes with completely different thresholds. This configuration helps forestall useful resource monopolization by establishing separate processing lanes with applicable guardrails, so vital enterprise processes can keep vital computational assets whereas limiting the influence of resource-intensive operations.
Alternatively, you possibly can implement the answer utilizing the AWS Command Line Interface (AWS CLI).
Within the following instance, we create a brand new workgroup named test-workgroup inside an current namespace known as test-namespace. This makes it doable to create queues and set up related monitoring guidelines for every queue utilizing the next command:
You too can modify an current workgroup utilizing update-workgroup utilizing the next command:
Greatest practices for queue administration
Take into account the next finest practices:
- Begin easy – Start with a minimal set of queues and guidelines
- Align with enterprise priorities – Configure queues to mirror vital enterprise processes
- Monitor and regulate – Frequently overview queue efficiency and regulate thresholds
- Take a look at earlier than manufacturing – Validate question metrics conduct in a take a look at setting earlier than making use of to manufacturing
Clear up
To wash up your assets, delete the Amazon Redshift Serverless workgroups and namespaces. For directions, see Deleting a workgroup.
Conclusion
Question queues in Amazon Redshift Serverless bridge the hole between serverless simplicity and fine-grained workload management by enabling queue-specific Question Monitoring Guidelines tailor-made to completely different analytical workloads. By isolating workloads and implementing focused useful resource thresholds, you possibly can defend business-critical queries, enhance efficiency predictability, and restrict runaway queries, serving to reduce surprising useful resource consumption and higher management prices, whereas nonetheless benefiting from the automated scaling and operational simplicity of Redshift Serverless.
Get began with Amazon Redshift Serverless as we speak.
In regards to the authors