

{kind=link}

|
Twenty years in the past at the moment, on March 14, 2006, Amazon Easy Storage Service (Amazon S3) quietly launched with a modest one-paragraph announcement on the What’s New web page:
Amazon S3 is storage for the Web. It’s designed to make web-scale computing simpler for builders. Amazon S3 supplies a easy net providers interface that can be utilized to retailer and retrieve any quantity of knowledge, at any time, from anyplace on the net. It provides any developer entry to the identical extremely scalable, dependable, quick, cheap knowledge storage infrastructure that Amazon makes use of to run its personal international community of internet sites.
Even Jeff Barr’s weblog publish was just a few paragraphs, written earlier than catching a aircraft to a developer occasion in California. No code examples. No demo. Very low fanfare. No person knew on the time that this launch would form our complete business.
The early days: Constructing blocks that simply work
At its core, S3 launched two easy primitives: PUT to retailer an object and GET to retrieve it later. However the true innovation was the philosophy behind it: create constructing blocks that deal with the undifferentiated heavy lifting, which freed builders to concentrate on higher-level work.
From day one, S3 was guided by 5 fundamentals that stay unchanged at the moment.
Safety means your knowledge is protected by default. Sturdiness is designed for 11 nines (99.999999999%), and we function S3 to be lossless. Availability is designed into each layer, with the belief that failure is at all times current and should be dealt with. Efficiency is optimized to retailer just about any quantity of knowledge with out degradation. Elasticity means the system routinely grows and shrinks as you add and take away knowledge, with no guide intervention required.
Once we get this stuff proper, the service turns into so easy that the majority of you by no means have to consider how advanced these ideas are.
S3 at the moment: Scale past creativeness
All through 20 years, S3 has remained dedicated to its core fundamentals even because it’s grown to a scale that’s exhausting to understand.
When S3 first launched, it supplied roughly one petabyte of whole storage capability throughout about 400 storage nodes in 15 racks spanning three knowledge facilities, with 15 Gbps of whole bandwidth. We designed the system to retailer tens of billions of objects, with a most object dimension of 5 GB. The preliminary worth was 15 cents per gigabyte.
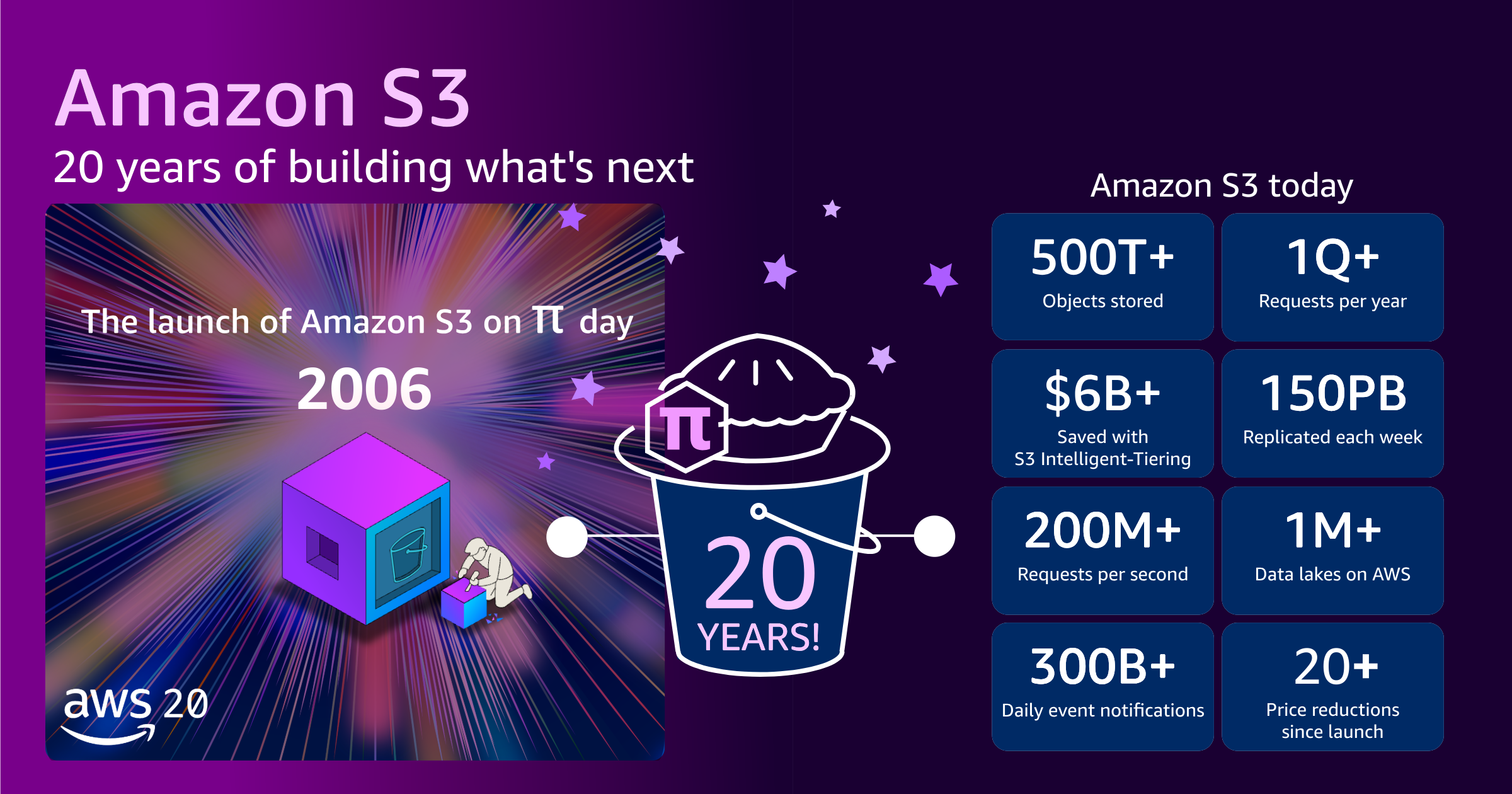
In the present day, S3 shops greater than 500 trillion objects and serves greater than 200 million requests per second globally throughout tons of of exabytes of knowledge in 123 Availability Zones in 39 AWS Areas, for thousands and thousands of consumers. The most object dimension has grown from 5 GB to 50 TB, a ten,000 fold improve. If you happen to stacked the entire tens of thousands and thousands S3 exhausting drives on prime of one another, they might attain the Worldwide Area Station and nearly again.
At the same time as S3 has grown to assist this unimaginable scale, the worth you pay has dropped. In the present day, AWS costs barely over 2 cents per gigabyte. That’s a worth discount of roughly 85% since launch in 2006. In parallel, we’ve continued to introduce methods to additional optimize storage spend with storage tiers. For instance, our prospects have collectively saved greater than $6 billion in storage prices through the use of Amazon S3 Clever-Tiering as in comparison with Amazon S3 Normal.
Over the previous 20 years, the S3 API has been adopted and used as a reference level throughout the storage business. A number of distributors now supply S3 appropriate storage instruments and methods, implementing the identical API patterns and conventions. This implies expertise and instruments developed for S3 typically switch to different storage methods, making the broader storage panorama extra accessible.
Regardless of all of this development and business adoption, maybe essentially the most outstanding achievement is that this: the code you wrote for S3 in 2006 nonetheless works at the moment, unchanged. Your knowledge went by 20 years of innovation and technical advances. We migrated the infrastructure by a number of generations of disks and storage methods. All of the code to deal with a request has been rewritten. However the knowledge you saved 20 years in the past remains to be accessible at the moment, and we’ve maintained full API backward compatibility. That’s our dedication to delivering a service that regularly “simply works.”
The engineering behind the size
What makes S3 potential at this scale? Steady innovation in engineering.
A lot of what follows is drawn from a dialog between Mai-Lan Tomsen Bukovec, VP of Knowledge and Analytics at AWS, and Gergely Orosz of The Pragmatic Engineer. The in-depth interview goes additional into the technical particulars for many who wish to go deeper. Within the following paragraphs, I share some examples:
On the coronary heart of S3 sturdiness is a system of microservices that repeatedly examine each single byte throughout the complete fleet. These auditor providers look at knowledge and routinely set off restore methods the second they detect indicators of degradation. S3 is designed to be lossless: the 11 nines design purpose displays how the replication issue and re-replication fleet are sized, however the system is constructed in order that objects aren’t misplaced.
S3 engineers use formal strategies and automatic reasoning in manufacturing to mathematically show correctness. When engineers test in code to the index subsystem, automated proofs confirm that consistency hasn’t regressed. This similar method proves correctness in cross-Area replication or for entry insurance policies.
Over the previous 8 years, AWS has been progressively rewriting performance-critical code within the S3 request path in Rust. Blob motion and disk storage have been rewritten, and work is actively ongoing throughout different parts. Past uncooked efficiency, Rust’s sort system and reminiscence security ensures eradicate complete lessons of bugs at compile time. That is an important property when working at S3 scale and correctness necessities.
S3 is constructed on a design philosophy: “Scale is to your benefit.” Engineers design methods in order that elevated scale improves attributes for all customers. The bigger S3 will get, the extra de-correlated workloads change into, which improves reliability for everybody.
Wanting ahead
The imaginative and prescient for S3 extends past being a storage service to changing into the common basis for all knowledge and AI workloads. Our imaginative and prescient is straightforward: you retailer any sort of knowledge one time in S3, and you’re employed with it immediately, with out transferring knowledge between specialised methods. This method reduces prices, eliminates complexity, and removes the necessity for a number of copies of the identical knowledge.
Listed here are just a few standout launches from current years:
- S3 Tables – Absolutely managed Apache Iceberg tables with automated upkeep that optimize question effectivity and scale back storage price over time.
- S3 Vectors – Native vector storage for semantic search and RAG, supporting as much as 2 billion vectors per index with sub-100ms question latency. In solely 5 months (July–December 2025), you created greater than 250,000 indices, ingested greater than 40 billion vectors, and carried out greater than 1 billion queries.
- S3 Metadata – Centralized metadata for fast knowledge discovery, eradicating the necessity to recursively listing massive buckets for cataloging and considerably decreasing time-to-insight for big knowledge lakes.
Every of those capabilities operates at S3 price construction. You possibly can deal with a number of knowledge varieties that historically required costly databases or specialised methods however are actually economically possible at scale.
From 1 petabyte to tons of of exabytes. From 15 cents to 2 cents per gigabyte. From easy object storage to the muse for AI and analytics. By all of it, our 5 fundamentals–safety, sturdiness, availability, efficiency, and elasticity–stay unchanged, and your code from 2006 nonetheless works at the moment.
Right here’s to the following 20 years of innovation on Amazon S3.