

{kind=link}
Immediately, Databricks’s help of Iceberg v3 enters Public Preview, unlocking the newest improvements from the Iceberg group natively on the open lakehouse.
Iceberg v3 marks a significant step ahead for open desk codecs, unlocking use instances throughout incremental knowledge processing and semi-structured knowledge evaluation which beforehand required brittle workarounds. Past this, Iceberg v3 represents a big technological innovation by additional unifying the information layer of Iceberg and Delta Lake, eliminating the necessity to rewrite knowledge when constructing interoperable pipelines.
Right here’s what’s new in Iceberg v3, why it issues, and why Databricks is the most effective place to run your lakehouse.
What’s new in Iceberg v3?
Unity Catalog Managed Iceberg v3 tables help Row Lineage, Deletion Vectors, and VARIANT, unlocking new use instances and important efficiency advantages. Databricks may interoperate with these options on overseas Iceberg tables (Iceberg tables registered in different catalogs), enabling clients to construct brokers and AI functions in opposition to their knowledge, no matter the place it lives.
Incremental Processing at Scale: Row Lineage and Deletion Vectors
Most knowledge arrives as a stream of modifications (INSERTs, UPDATEs, MERGEs, DELETEs) somewhat than in batches, sometimes sourced from operational databases, occasion streams, and third-party APIs. Traditionally, processing these modifications required fixing two exhausting issues:
- Figuring out which rows modified in bronze datasets
- Making use of these modifications effectively to silver/gold datasets
Groups normally resorted to full desk scans or exterior CDC programs to detect modifications, and costly file rewrites to use them. This resulted in pipelines that have been gradual, expensive to keep up, and susceptible to drift and knowledge silos.
Now, row lineage permits groups to rapidly determine which rows modified. Each row in an Iceberg v3 desk carries a everlasting row ID and a sequence quantity reflecting when the row was final modified.
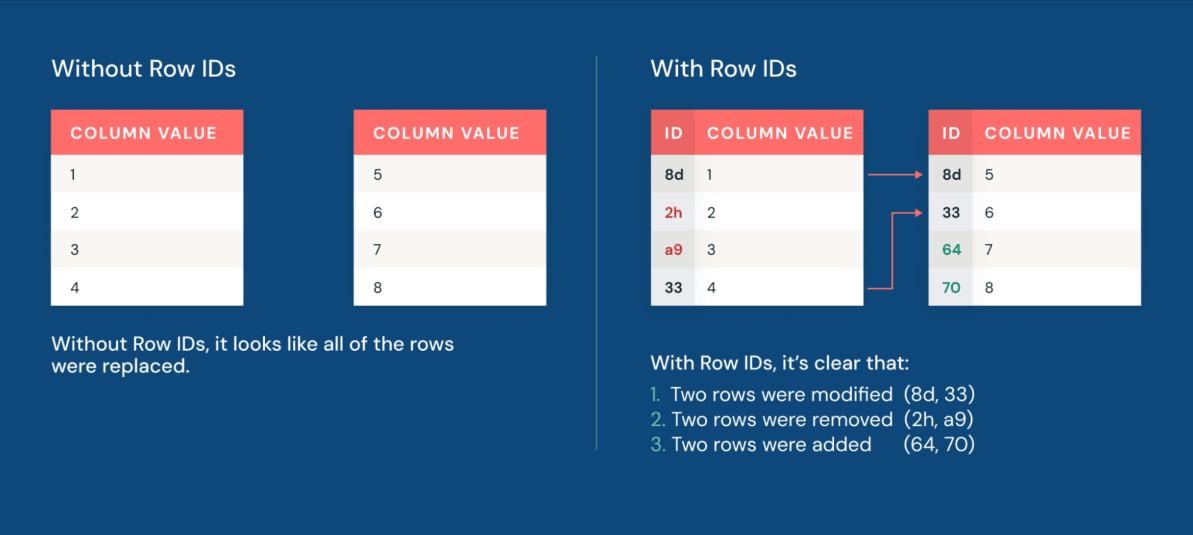
Moreover, deletion vectors make making use of modifications to datasets extra performant than ever. Deletion vectors enable Iceberg to trace which rows have been logically deleted with out instantly rewriting the underlying knowledge information. As a substitute of bodily deleting rows by rewriting giant Parquet information, the engine writes a light-weight delete file alongside the information. The result’s knowledge manipulation efficiency that’s as much as 10x sooner than the normal copy-on-write strategy.

With Deletion Vectors now native to Iceberg, Geodis can construct its Iceberg Lakehouse on Databricks with out compromising efficiency or engine selection.
“Now that Deletion Vectors have come to Iceberg, we are able to centralize our Iceberg knowledge property in Unity Catalog, whereas leveraging the engine of our selection and sustaining best-in-class efficiency.” — Delio Amato, Chief Architect & Knowledge Officer, Geodis
Collectively, row lineage and deletion vectors make CDC a local property of the desk itself. Groups can construct pipelines that target incrementally processing solely what really modified, slicing prices and driving sooner time-to-insight for each analyst and knowledge scientist downstream.

Semi-Structured Knowledge as a First-Class Citizen by way of VARIANT
Logs, API responses, clickstreams, and IoT payloads are very invaluable semi-structured knowledge sources. As they evolve, AI fashions can adapt alongside them, studying instantly from altering real-world alerts.
Nevertheless, traditionally, knowledge groups confronted a painful tradeoff when working with semi-structured knowledge. One customary strategy was to implement inflexible schemas, however this led to brittle pipelines that broke each time the upstream knowledge advanced. One other canonical workaround was to retailer the information as uncooked string dumps, however this made queries very advanced and gradual. Neither strategy was scalable.
The Iceberg v3 VARIANT sort resolves this tradeoff. VARIANT is a local column sort that shops semi-structured payloads alongside relational columns in the identical Iceberg desk. This doesn’t require any flattening, storage in a separate system, or an ETL pipeline for normalization. Relatively, knowledge groups can ingest uncooked semi-structured knowledge as-is and question it with customary SQL.

Panther makes use of VARIANT to energy large-scale ingestion and analytics throughout semi-structured safety logs.
“Unity Catalog and Iceberg v3 unlock the facility of semi-structured knowledge via VARIANT. This permits interoperability and cost-effective, petabyte-scale log assortment.” — Russell Leighton, Chief Architect, Panther
With VARIANT, your AI fashions and analytics pipelines work instantly in opposition to reside, evolving knowledge in a single ruled desk. When new fields seem in API responses or new occasion sorts enter clickstreams, they’re queryable instantly and not using a schema migration. With efficiency optimizations like shredding, clients can profit from columnar-like efficiency on their semi-structured knowledge, unlocking low-latency BI, dashboards, and alerting pipelines.
Unity Catalog delivers interoperability and efficiency for multi-engine, multi-catalog enterprises
Trendy enterprises depend on a number of engines and catalogs to help numerous use instances throughout enterprise items and legacy programs. Unity Catalog was designed to allow interoperability and governance throughout catalogs, whereas additionally optimizing knowledge layouts primarily based on question patterns.
Unified governance throughout catalogs and engines
Unity Catalog’s open APIs enable clients to put in writing as soon as and skim anyplace – no extra knowledge duplication or siloed entry controls. UC can federate to different Iceberg catalogs, enabling bi-directional interoperability. All Iceberg knowledge in Snowflake, AWS Glue, Salesforce, and different main catalogs, could be learn by Unity Catalog, and all knowledge in UC could be accessed by those self same third get together platforms by way of open APIs.
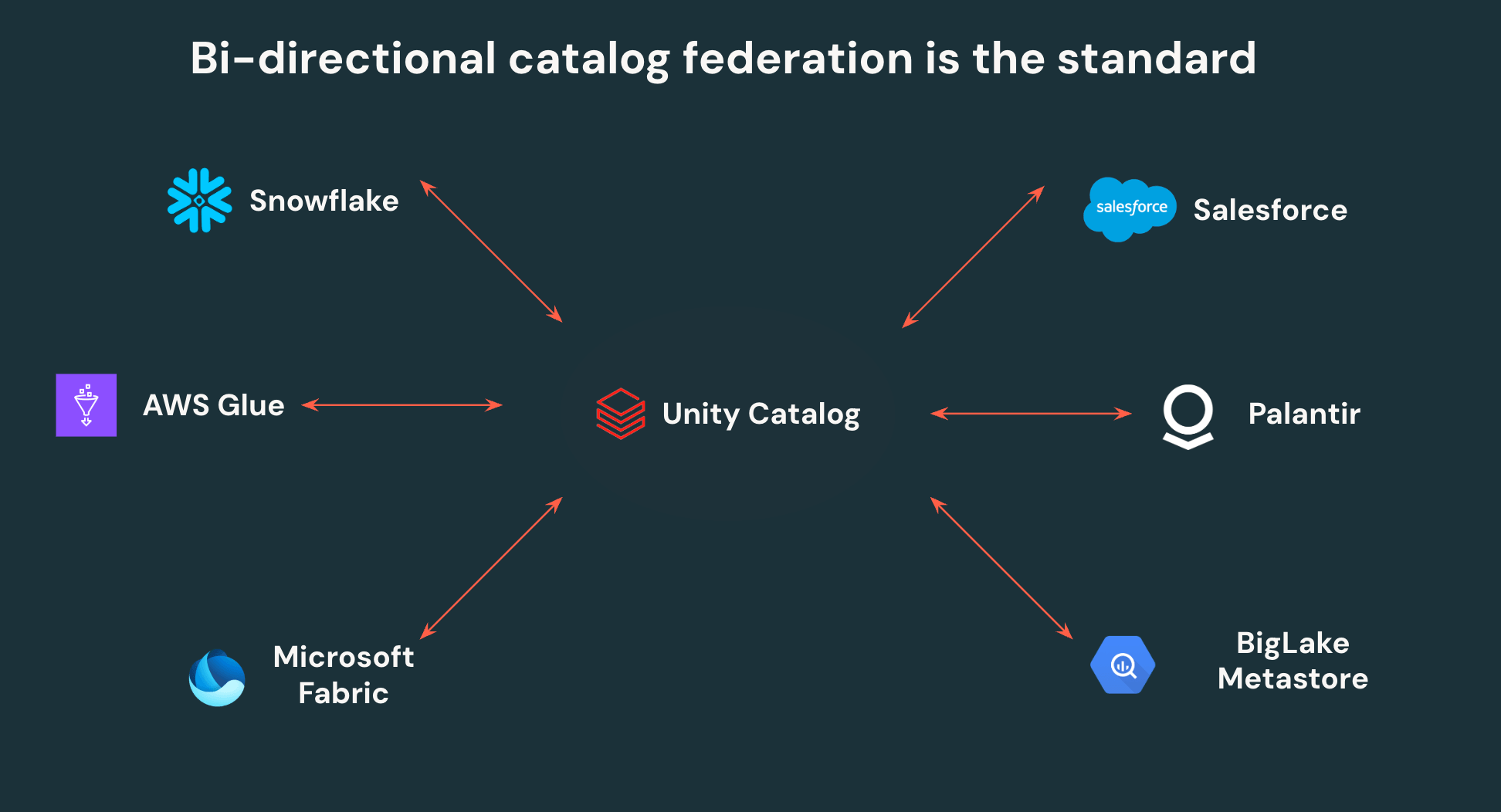
Past this, Unity Catalog is the primary catalog to help fine-grained entry management on exterior engines, empowering groups to outline row filters and column masks as soon as and have them enforced all over the place knowledge is accessed. Centralizing governance on Unity Catalog makes it considerably simpler for safety groups to manipulate and monitor their lakehouse, whereas additionally giving knowledge groups autonomy to level any instrument at their lakehouse.

Delta and Iceberg interoperability
Delta Lake with UniForm unlocks interoperability throughout clients’ Delta Lake and Iceberg ecosystems: write as soon as to Delta Lake, and skim as Iceberg from Snowflake, BigQuery, Redshift, Athena, Trino, or another Iceberg engine. With Iceberg v3 adopting Deletion Vectors, Row Lineage, and VARIANT natively, clients not face a tradeoff between Delta Lake efficiency options and Iceberg compatibility. The result’s a single copy of knowledge that serves each engine in your stack, with no replication pipelines to keep up or threat of drift. A number one monetary providers supplier changed a expensive full-table replication service with UniForm, letting Snowflake learn instantly from Unity Catalog managed tables.
Automated efficiency and optimization
Past interoperability, Databricks brings efficiency, format optimization, and governance collectively in a single system so groups don’t need to sew these capabilities collectively themselves. Databricks combines clever upkeep (Predictive Optimization), bodily format optimizations primarily based on question patterns (Automated Liquid Clustering), and cross-engine governance (Unity Catalog) in a single layer, with no handbook configuration required.
Different managed Iceberg choices require groups to handle desk upkeep, file format, and entry coverage enforcement independently. On Databricks, these capabilities are unified and computerized, eradicating a complete class of operational overhead whereas additionally preserving full knowledge portability.
Get Began with Apache Iceberg v3 on Databricks
Iceberg v3 on Databricks is Public Preview right this moment! Groups can now reap the benefits of the most effective options throughout Delta and Iceberg with out buying and selling off between efficiency and interoperability.
Iceberg v3 is out there on Databricks Runtime 18.0+ with Unity Catalog enabled.
Making a Unity Catalog managed Iceberg desk with v3 enabled is straightforward:
Making a Unity Catalog managed Delta desk with UniForm and v3 enabled is simply as easy:
Wanting forward: Iceberg v4
Iceberg v3 unifies the information layer throughout Delta and Iceberg on a performant, interoperable basis – the subsequent frontier is the metadata layer. Databricks engineers are actively driving a number of core Iceberg v4 proposals within the Apache group to make metadata easier, sooner and extra scalable. These embrace the adaptive metadata tree, which simplifies the metadata construction so that the majority operations require writing solely a single file as a substitute of a number of. Further proposals embrace relative path help for seamless desk relocation throughout environments and a modernized statistics mannequin that extends to newer knowledge sorts like VARIANT and GEOMETRY. Collectively, these developments will imply sooner ingestion, extra environment friendly question planning, and easier desk administration at enterprise scale. We’re excited to proceed advancing the Iceberg specification with the group.
Study extra at Knowledge and AI Summit
Get began with Iceberg v3 and be part of us on the upcoming Knowledge and AI Summit in San Francisco, June 15-18, 2026, to be taught extra about our Iceberg roadmap and work throughout the ecosystem.