
{kind=link}
PyCaret is an open-source, low-code machine studying library that simplifies and standardizes the end-to-end machine studying workflow. As a substitute of performing as a single AutoML algorithm, PyCaret capabilities as an experiment framework that wraps many common machine studying libraries beneath a constant and extremely productive API
This design selection issues. PyCaret doesn’t absolutely automate decision-making behind the scenes. It accelerates repetitive work corresponding to preprocessing, mannequin comparability, tuning, and deployment, whereas maintaining the workflow clear and controllable.
Positioning PyCaret within the ML Ecosystem
PyCaret is finest described as an experiment orchestration layer reasonably than a strict AutoML engine. Whereas many AutoML instruments concentrate on exhaustive mannequin and hyperparameter search, PyCaret focuses on decreasing human effort and boilerplate code.
This philosophy aligns with the “citizen information scientist” idea popularized by Gartner, the place productiveness and standardization are prioritized. PyCaret additionally attracts inspiration from the caret library in R, emphasizing consistency throughout mannequin households.
Core Experiment Lifecycle
Throughout classification, regression, time sequence, clustering, and anomaly detection, PyCaret enforces the identical lifecycle:
setup()initializes the experiment and builds the preprocessing pipelinecompare_models()benchmarks candidate fashions utilizing cross-validationcreate_model()trains a specific estimator- Non-compulsory tuning or ensembling steps
finalize_model()retrains the mannequin on the complete datasetpredict_model(),save_model(), ordeploy_model()for inference and deployment
The separation between analysis and finalization is essential. As soon as a mannequin is finalized, the unique holdout information turns into a part of coaching, so correct analysis should happen beforehand
Preprocessing as a First-Class Function
PyCaret treats preprocessing as a part of the mannequin, not a sidestep. All transformations corresponding to imputation, encoding, scaling, and normalization are captured in a single pipeline object. This pipeline is reused throughout inference and deployment, decreasing the chance of training-serving mismatch.
Superior choices embrace rare-category grouping, iterative imputation, textual content vectorization, pipeline caching, and parallel-safe information loading. These options make PyCaret appropriate not just for newbies, but in addition for severe utilized workflows
Constructing and Evaluating Fashions with PyCaret
Right here is the complete Colab hyperlink for the venture: Colab
Binary Classification Workflow
This instance reveals a whole classification experiment utilizing PyCaret.
from pycaret.datasets import get_data
from pycaret.classification import *
# Load instance dataset
information = get_data("juice")
# Initialize experiment
exp = setup(
information=information,
goal="Buy",
session_id=42,
normalize=True,
remove_multicollinearity=True,
log_experiment=True
)
# Examine all accessible fashions
best_model = compare_models()
# Examine efficiency on holdout information
holdout_preds = predict_model(best_model)
# Prepare ultimate mannequin on full dataset
final_model = finalize_model(best_model)
# Save pipeline + mannequin
save_model(final_model, "juice_purchase_model")What this demonstrates:
setup()builds a full preprocessing pipelinecompare_models()benchmarks many algorithms with one namefinalize_model()retrains utilizing all accessible information- The saved artifact contains preprocessing and mannequin collectively

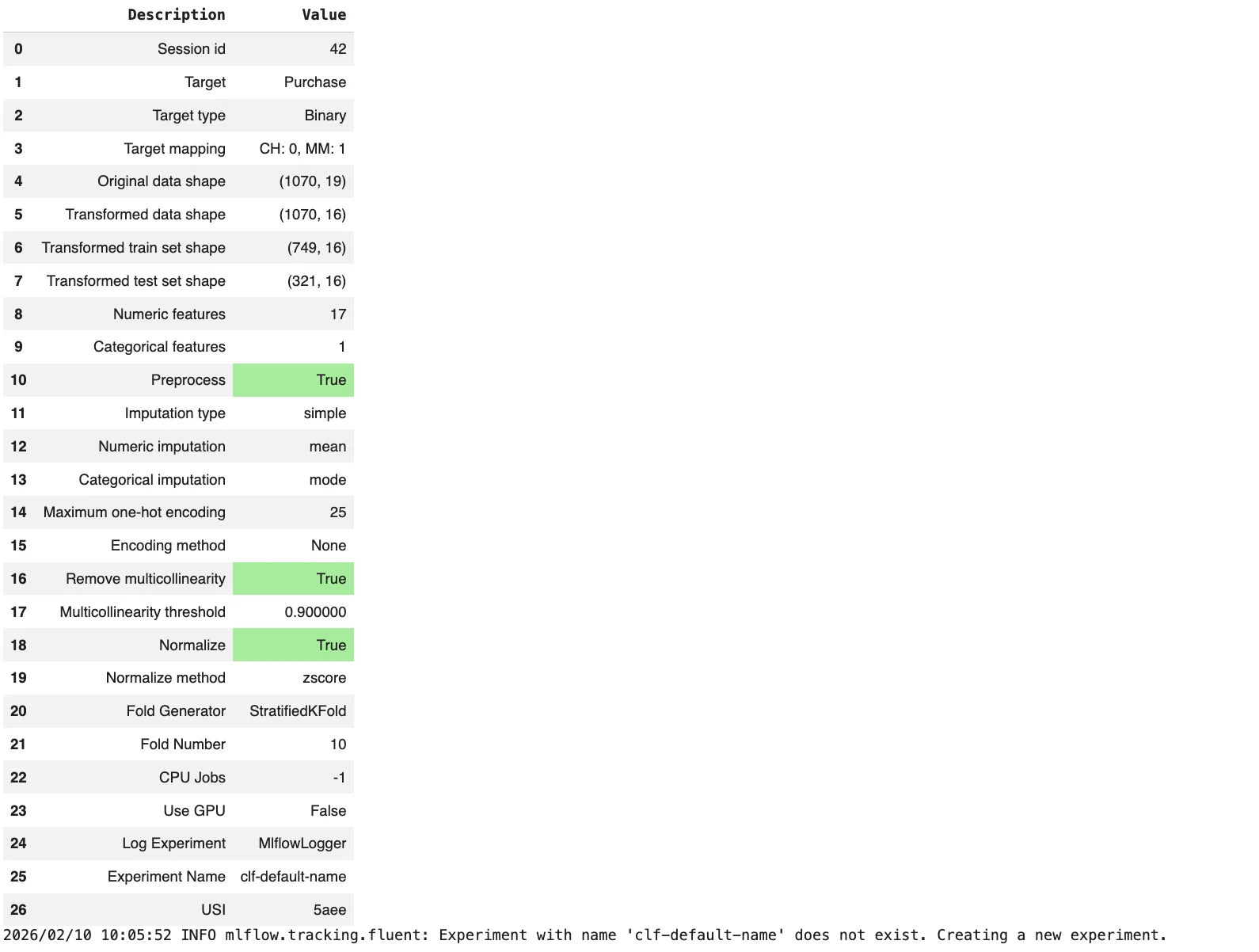
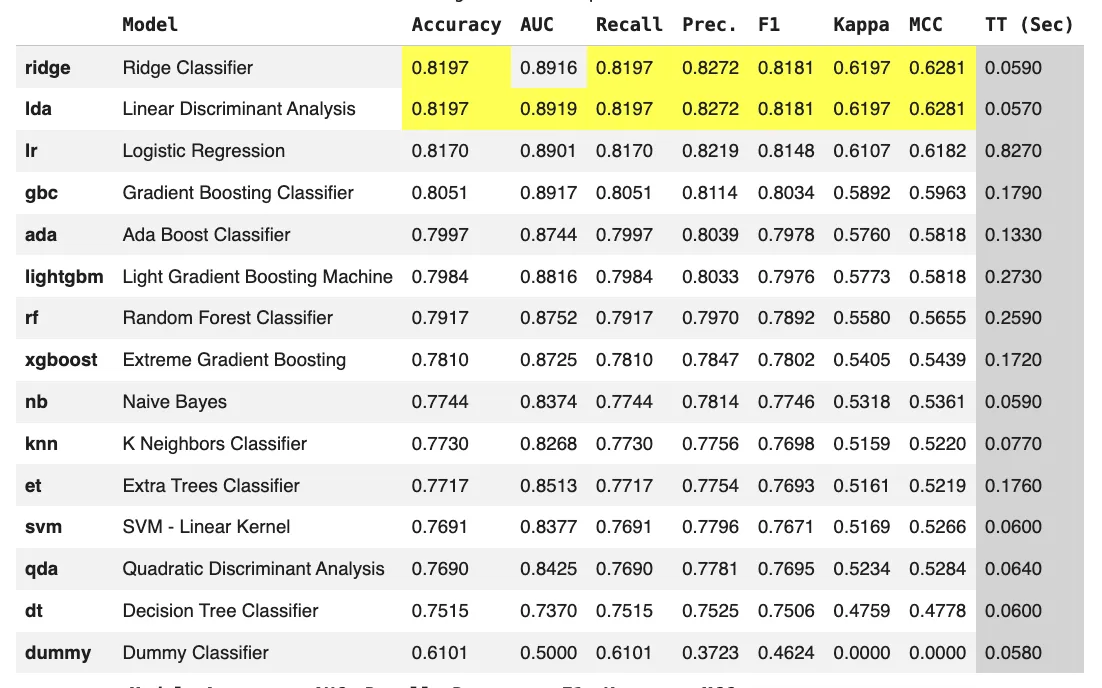

From the output, we will see that the dataset is dominated by numeric options and advantages from normalization and multicollinearity removing. Linear fashions corresponding to Ridge Classifier and LDA obtain one of the best efficiency, indicating a largely linear relationship between pricing, promotions, and buy conduct. The finalized Ridge mannequin reveals improved accuracy when skilled on the complete dataset, and the saved pipeline ensures constant preprocessing and inference.
Regression with Customized Metrics
from pycaret.datasets import get_data
from pycaret.regression import *
information = get_data("boston")
exp = setup(
information=information,
goal="medv",
session_id=123,
fold=5
)
top_models = compare_models(kind="RMSE", n_select=3)
tuned = tune_model(top_models[0])
ultimate = finalize_model(tuned)Right here, PyCaret permits quick comparability whereas nonetheless enabling tuning and metric-driven choice.
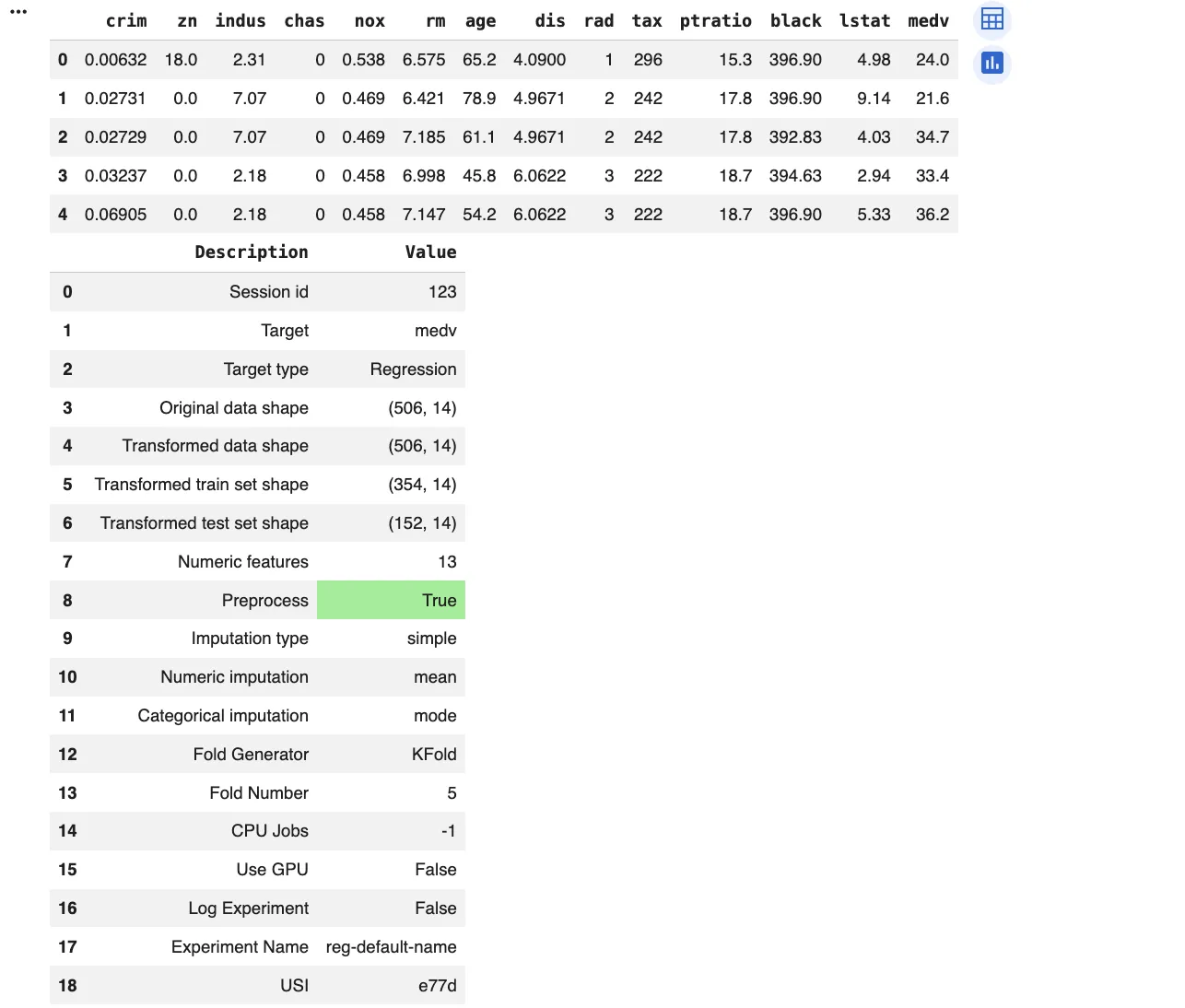
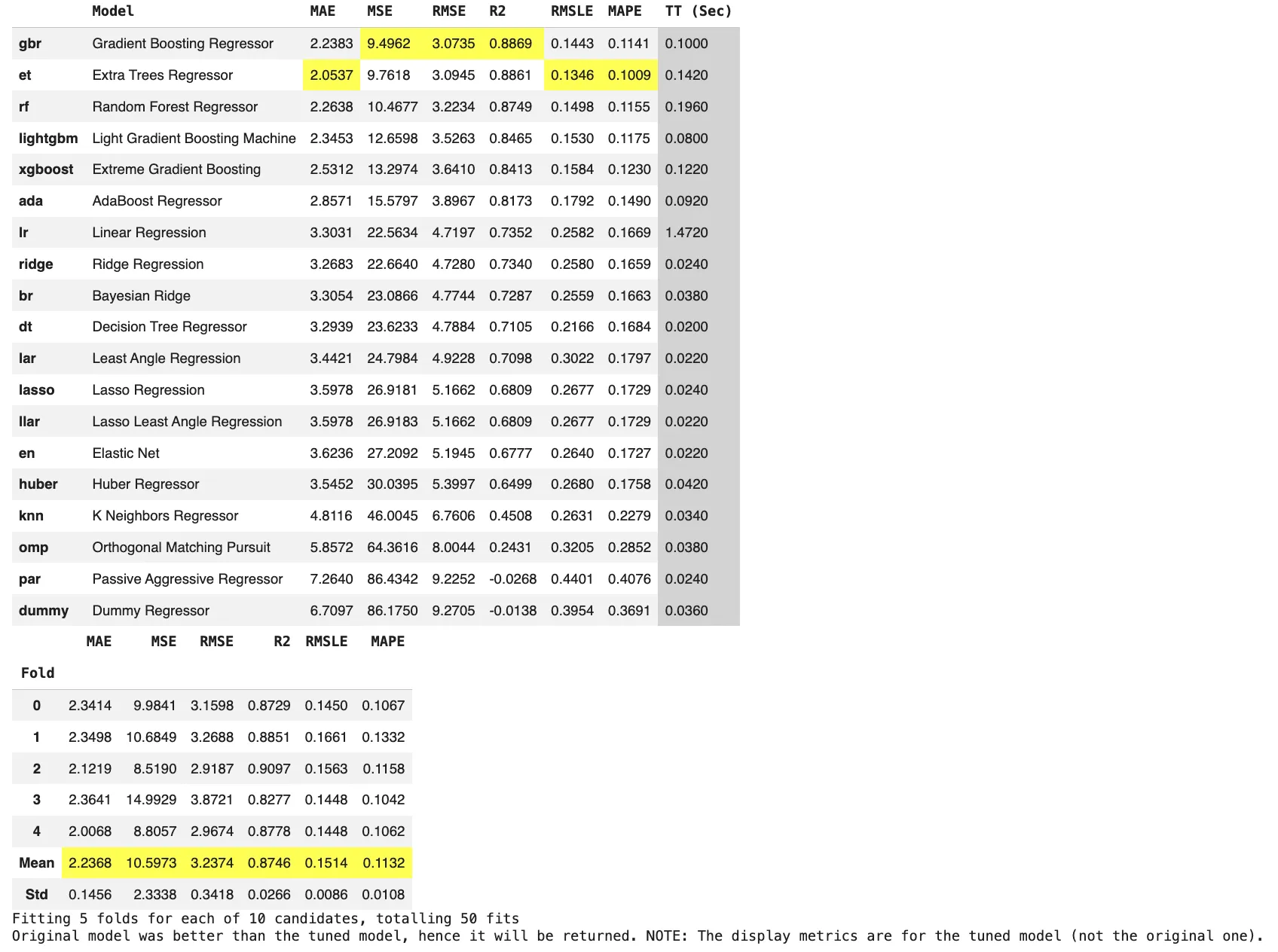
From the output, we will see that the dataset is absolutely numeric and properly fitted to tree-based fashions. Ensemble strategies corresponding to Gradient Boosting, Additional Bushes, and Random Forest clearly outperform linear fashions, attaining increased R2 scores, and decrease error metrics. This means robust nonlinear relationships between options like crime charges, rooms, location elements, and home costs. Linear and sparse fashions carry out considerably worse, confirming that easy linear assumptions are inadequate for this drawback.
Time Collection Forecasting
from pycaret.datasets import get_data
from pycaret.time_series import *
y = get_data("airline")
exp = setup(
information=y,
fh=12,
session_id=7
)
finest = compare_models()
forecast = predict_model(finest) 

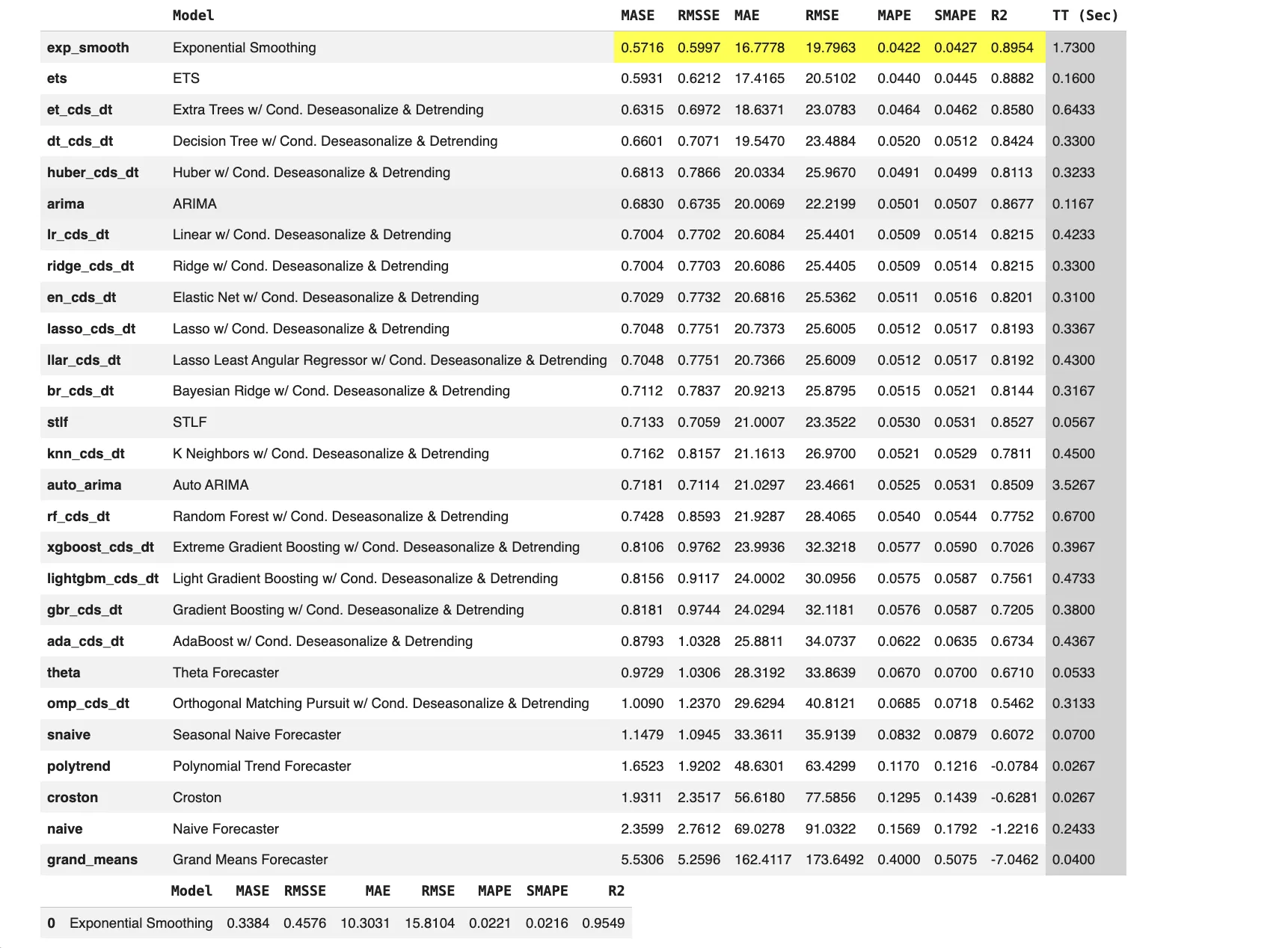
From the output, we will see that the sequence is strictly constructive and reveals robust multiplicative seasonality with a main seasonal interval of 12, confirming a transparent yearly sample. The really helpful differencing values additionally point out each pattern and seasonal elements are current.
Exponential Smoothing performs finest, attaining the bottom error metrics and highest R2, displaying that classical statistical fashions deal with this seasonal construction very properly. Machine studying based mostly fashions with deseasonalization carry out moderately however don’t outperform the highest statistical strategies for this univariate seasonal dataset.
This instance highlights how PyCaret adapts the identical workflow to forecasting by introducing time sequence ideas like forecast horizons, whereas maintaining the API acquainted.
Clustering
from pycaret.clustering import *
from pycaret.anomaly import *
# Clustering
exp_clust = setup(information, normalize=True)
kmeans = create_model("kmeans")
clusters = assign_model(kmeans)
From the output we will see that the clustering experiment was run on absolutely numeric information with preprocessing enabled, together with imply imputation and z-score normalization. The silhouette rating is comparatively low, indicating weak cluster separation. Calinski–Harabasz and Davies–Bouldin scores counsel overlapping clusters reasonably than clearly distinct teams. Homogeneity, Rand Index, and Completeness are zero, which is predicted in an unsupervised setting with out floor reality labels.
Classification fashions supported within the built-in mannequin library
PyCaret’s classification module helps supervised studying with categorical goal variables. The create_model() operate accepts an estimator ID from the built-in mannequin library or a scikit-learn suitable estimator object.
The desk beneath lists the classification estimator IDs and their corresponding mannequin names.
| Estimator ID | Mannequin title in PyCaret |
| lr | Logistic Regression |
| knn | Ok Neighbors Classifier |
| nb | Naive Bayes |
| dt | Determination Tree Classifier |
| svm | SVM Linear Kernel |
| rbfsvm | SVM Radial Kernel |
| gpc | Gaussian Course of Classifier |
| mlp | MLP Classifier |
| ridge | Ridge Classifier |
| rf | Random Forest Classifier |
| qda | Quadratic Discriminant Evaluation |
| ada | Ada Increase Classifier |
| gbc | Gradient Boosting Classifier |
| lda | Linear Discriminant Evaluation |
| et | Additional Bushes Classifier |
| xgboost | Excessive Gradient Boosting |
| lightgbm | Mild Gradient Boosting Machine |
| catboost | CatBoost Classifier |
When evaluating many fashions, a number of classification particular particulars matter. The compare_models() operate trains and evaluates all accessible estimators utilizing cross-validation. It then types the outcomes by a specific metric, with accuracy utilized by default. For binary classification, the probability_threshold parameter controls how predicted possibilities are transformed into class labels. The default worth is 0.5 except it’s modified. For bigger or scaled runs, a use_gpu flag will be enabled for supported algorithms, with extra necessities relying on the mannequin.
Regression fashions supported within the built-in mannequin library
PyCaret’s regression module makes use of the identical mannequin library by ID sample as classification. The create_model() operate accepts an estimator ID from the built-in library or any scikit-learn suitable estimator object.
The desk beneath lists the regression estimator IDs and their corresponding mannequin names.
| Estimator ID | Mannequin title in PyCaret |
| lr | Linear Regression |
| lasso | Lasso Regression |
| ridge | Ridge Regression |
| en | Elastic Internet |
| lar | Least Angle Regression |
| llar | Lasso Least Angle Regression |
| omp | Orthogonal Matching Pursuit |
| br | Bayesian Ridge |
| ard | Computerized Relevance Willpower |
| par | Passive Aggressive Regressor |
| ransac | Random Pattern Consensus |
| tr | TheilSen Regressor |
| huber | Huber Regressor |
| kr | Kernel Ridge |
| svm | Help Vector Regression |
| knn | Ok Neighbors Regressor |
| dt | Determination Tree Regressor |
| rf | Random Forest Regressor |
| et | Additional Bushes Regressor |
| ada | AdaBoost Regressor |
| gbr | Gradient Boosting Regressor |
| mlp | MLP Regressor |
| xgboost | Excessive Gradient Boosting |
| lightgbm | Mild Gradient Boosting Machine |
| catboost | CatBoost Regressor |
These regression fashions will be grouped by how they usually behave in follow. Linear and sparse linear households corresponding to lr, lasso, ridge, en, lar, and llar are sometimes used as quick baselines. They practice rapidly and are simpler to interpret. Tree based mostly ensembles and boosting households corresponding to rf, et, ada, gbr, and the gradient boosting libraries xgboost, lightgbm, and catboost typically carry out very properly on structured tabular information. They’re extra complicated and extra delicate to tuning and information leakage if preprocessing is just not dealt with fastidiously. Kernel and neighborhood strategies corresponding to svm, kr, and knn can mannequin non linear relationships. They will change into computationally costly on giant datasets and often require correct function scaling.
Time sequence forecasting fashions supported within the built-in mannequin library
PyCaret gives a devoted time sequence module constructed round forecasting ideas such because the forecast horizon (fh). It helps sktime suitable estimators. The set of obtainable fashions is determined by the put in libraries and the experiment configuration, so availability can fluctuate throughout environments.
The desk beneath lists the estimator IDs and mannequin names supported within the built-in time sequence mannequin library.
| Estimator ID | Mannequin title in PyCaret |
| naive | Naive Forecaster |
| grand_means | Grand Means Forecaster |
| snaive | Seasonal Naive Forecaster |
| polytrend | Polynomial Development Forecaster |
| arima | ARIMA household of fashions |
| auto_arima | Auto ARIMA |
| exp_smooth | Exponential Smoothing |
| stlf | STL Forecaster |
| croston | Croston Forecaster |
| ets | ETS |
| theta | Theta Forecaster |
| tbats | TBATS |
| bats | BATS |
| prophet | Prophet Forecaster |
| lr_cds_dt | Linear with Conditional Deseasonalize and Detrending |
| en_cds_dt | Elastic Internet with Conditional Deseasonalize and Detrending |
| ridge_cds_dt | Ridge with Conditional Deseasonalize and Detrending |
| lasso_cds_dt | Lasso with Conditional Deseasonalize and Detrending |
| llar_cds_dt | Lasso Least Angle with Conditional Deseasonalize and Detrending |
| br_cds_dt | Bayesian Ridge with Conditional Deseasonalize and Detrending |
| huber_cds_dt | Huber with Conditional Deseasonalize and Detrending |
| omp_cds_dt | Orthogonal Matching Pursuit with Conditional Deseasonalize and Detrending |
| knn_cds_dt | Ok Neighbors with Conditional Deseasonalize and Detrending |
| dt_cds_dt | Determination Tree with Conditional Deseasonalize and Detrending |
| rf_cds_dt | Random Forest with Conditional Deseasonalize and Detrending |
| et_cds_dt | Additional Bushes with Conditional Deseasonalize and Detrending |
| gbr_cds_dt | Gradient Boosting with Conditional Deseasonalize and Detrending |
| ada_cds_dt | AdaBoost with Conditional Deseasonalize and Detrending |
| lightgbm_cds_dt | Mild Gradient Boosting with Conditional Deseasonalize and Detrending |
| catboost_cds_dt | CatBoost with Conditional Deseasonalize and Detrending |
Some fashions help a number of execution backends. An engine parameter can be utilized to modify between accessible backends for supported estimators, corresponding to selecting completely different implementations for auto_arima.
Past the built-in library: customized estimators, MLOps hooks, and eliminated modules
PyCaret is just not restricted to its inbuilt estimator IDs. You may move an untrained estimator object so long as it follows the scikit study model API. The fashions() operate reveals what is out there within the present surroundings. The create_model() operate returns a skilled estimator object. In follow, because of this any scikit study suitable mannequin can typically be managed inside the identical coaching, analysis, and prediction workflow.
PyCaret additionally contains experiment monitoring hooks. The log_experiment parameter in setup() permits integration with instruments corresponding to MLflow, Weights and Biases, and Comet. Setting it to True makes use of MLflow by default. For deployment workflows, deploy_model() and load_model() can be found throughout modules. These help cloud platforms corresponding to Amazon Net Companies, Google Cloud Platform, and Microsoft Azure via platform particular authentication settings.
Earlier variations of PyCaret included modules for NLP and affiliation rule mining. These modules have been eliminated in PyCaret 3. Importing pycaret.nlp or pycaret.arules in present variations leads to lacking module errors. Entry to these options requires PyCaret 2.x. In present variations, the supported floor space is proscribed to the lively modules in PyCaret 3.x.
Conclusion
PyCaret acts as a unified experiment framework reasonably than a single AutoML system. It standardizes the complete machine studying workflow throughout duties whereas remaining clear and versatile. The constant lifecycle throughout modules reduces boilerplate and lowers friction with out hiding core selections. Preprocessing is handled as a part of the mannequin, which improves reliability in actual deployments. Constructed-in mannequin libraries present breadth, whereas help for customized estimators retains the framework extensible. Experiment monitoring and deployment hooks make it sensible for utilized work. General, PyCaret balances productiveness and management, making it appropriate for each fast experimentation and severe production-oriented workflows.
Incessantly Requested Questions
A. PyCaret is an experiment framework that standardizes ML workflows and reduces boilerplate, whereas maintaining preprocessing, mannequin comparability, and tuning clear and consumer managed.
A. A PyCaret experiment follows setup, mannequin comparability, coaching, optionally available tuning, finalization on full information, after which prediction or deployment utilizing a constant lifecycle.
A. Sure. Any scikit study suitable estimator will be built-in into the identical coaching, analysis, and deployment pipeline alongside inbuilt fashions.
Hello, I’m Janvi, a passionate information science fanatic presently working at Analytics Vidhya. My journey into the world of information started with a deep curiosity about how we will extract significant insights from complicated datasets.
Login to proceed studying and luxuriate in expert-curated content material.