

{kind=link}
It is a visitor publish by Edijs Drezovs, CEO and Founding father of GOStack, Viesturs Kols, Information Architect at GOStack, and Krisjanis Beitans, Senior Information Engineer at GOStack, in partnership with AWS.
Yggdrasil Gaming develops and publishes on line casino video games globally, processing huge quantities of real-time gaming information for recreation efficiency analytics, participant conduct insights, and business intelligence. As Yggdrasil’s system grew, managing dual-cloud environments created operational overhead and restricted their capacity to implement superior analytics initiatives. This problem grew to become vital forward of the launch of the Sport in a Field resolution on AWS Market, which generates will increase in information quantity and complexity.
Yggdrasil Gaming decreased multi-cloud complexity and constructed a scalable analytics basis by migrating from Google BigQuery to AWS analytics providers. On this publish, you’ll uncover how Yggdrasil Gaming reworked their information structure to fulfill rising enterprise calls for. You’ll study sensible methods for migrating from proprietary programs to open desk codecs equivalent to Apache Iceberg whereas sustaining enterprise continuity.
Yggdrasil labored with GOStack, an AWS Companion, emigrate to an Apache Iceberg-based lakehouse structure. The migration helped cut back operational complexity and enabled real-time gaming analytics and machine studying.
Challenges
Yggdrasil confronted a number of vital challenges that prompted their migration to AWS:
- Multi-cloud operational complexity: Managing infrastructure throughout AWS and Google Cloud created important operational overhead, lowering agility and rising upkeep prices. The info workforce needed to preserve experience in each environments and coordinate information motion between clouds.
- Structure limitations: The prevailing setup couldn’t successfully help superior analytics and AI initiatives. Extra critically, the launch of Yggdrasil’s Sport in a Field resolution required a modernized, scalable information setting able to dealing with elevated information volumes and enabling superior analytics.
- Scalability constraints: The structure lacked the unified information basis with open requirements and automation required to scale effectively. As information volumes grew, prices elevated proportionally, and the workforce wanted an setting designed for contemporary analytics at scale.
Answer overview
Yggdrasil labored with GOStack, an AWS APN accomplice, to design their new lakehouse structure. The next diagram exhibits the excessive stage overview of this structure.
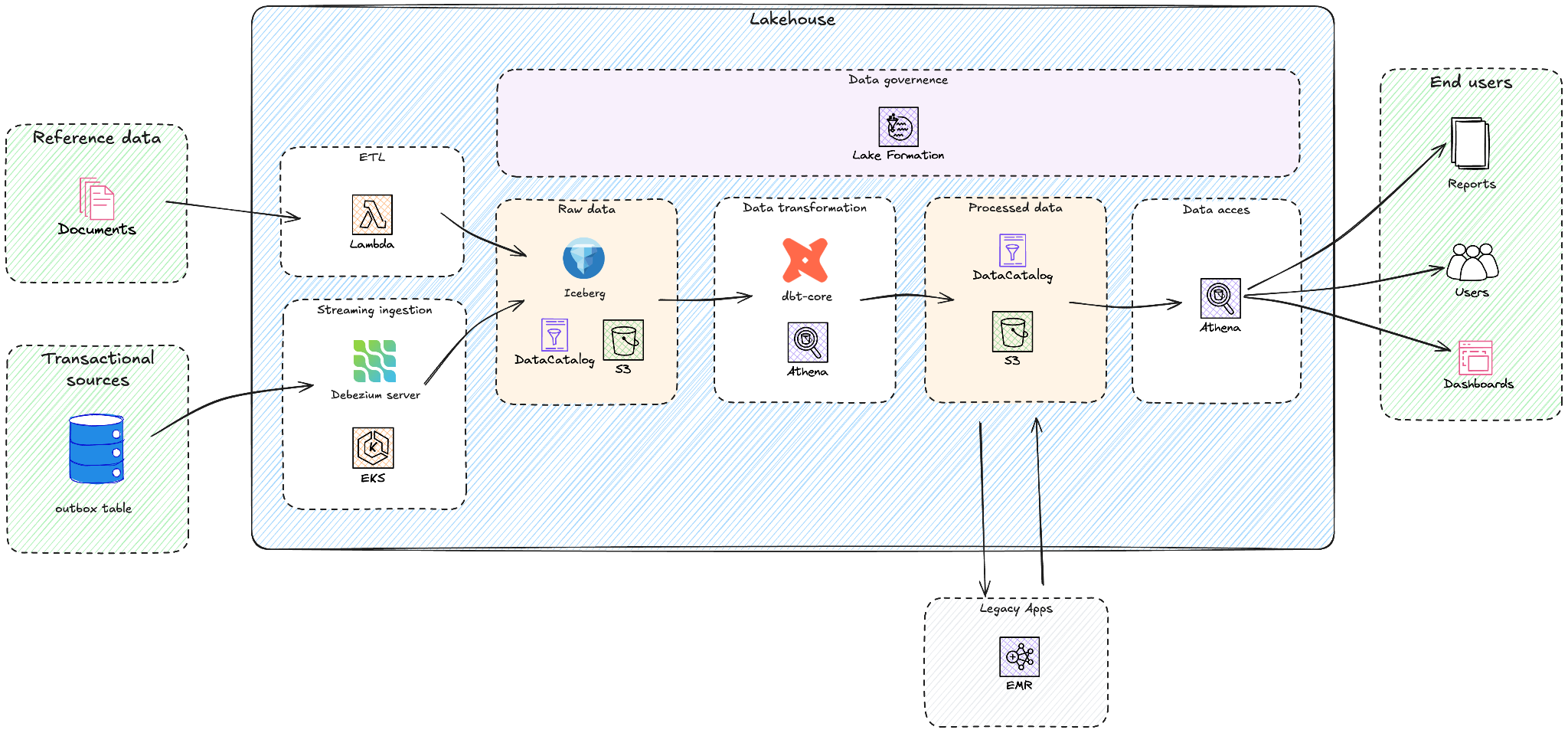

Yggdrasil efficiently migrated from Google BigQuery to an information lakehouse structure utilizing Amazon Athena, Amazon EMR, Amazon Easy Storage Service (Amazon S3), AWS Glue Information Catalog, AWS Lake Formation, Amazon Elastic Kubernetes Service (Amazon EKS) and AWS Lambda. Their strategic method goals to scale back multi-cloud complexity whereas constructing a scalable basis for his or her Sport in a Field resolution and particular AI/ML initiatives like customized recreation suggestions and fraud detection.
The mixture of Amazon S3, Apache Iceberg, and Amazon Athena allowed Yggdrasil to maneuver away from provisioned, always-on compute fashions. The Amazon Athena pay-per-query pricing fees just for information scanned, eradicating idle compute prices throughout off-peak durations. Inner value modeling carried out through the analysis section indicated that this structure may cut back analytics system prices by 30–50% in comparison with compute-based warehouse pricing fashions of different options, significantly for bursty workloads pushed by recreation launches, tournaments, and seasonal visitors. By adopting AWS-native analytics providers, Yggdrasil decreased operational complexity by means of native integration with AWS Identification and Entry Administration (AWS IAM), Amazon EKS, and AWS Lambda, serving to simplify safety, governance, and automation throughout the analytics system.
The answer facilities on a contemporary lakehouse structure constructed on Amazon S3, which supplies sturdy and cost-efficient storage for Iceberg tables in Apache Parquet format. Apache Iceberg desk format supplies ACID transactions, schema evolution, and time journey capabilities whereas sustaining an open customary. AWS Glue Information Catalog serves because the central technical metadata repository, whereas Amazon Athena acts because the serverless question engine utilized by dbt-athena and for ad-hoc information exploration. Amazon EMR runs Yggdrasil’s legacy Apache Spark utility in a completely managed setting, and AWS Lake Formation supplies centralized safety and governance for information lakes, permitting fine-grained entry management at database, desk, column, and row ranges.
The migration adopted a phased method:
- Set up lakehouse basis – Arrange Apache Iceberg-based structure with Amazon S3 with AWS Glue Information Catalog
- Implement real-time information ingestion – Deploy Debezium connectors for real-time change information seize from EKS and Google Kubernetes Engine (GKE) clusters
- Migrate processing pipelines – Re-system ETL pipelines utilizing AWS Lambda, and legacy information purposes re-systemed on Amazon EMR
- Modernizing the transformation layer – Implement dbt with Amazon Athena for modular, reusable fashions
- Allow governance – Configure AWS Lake Formation for complete information governance
Set up lakehouse basis
The primary section of the migration targeted on constructing a strong basis for the brand new information lakehouse structure on AWS. The purpose was to create a scalable, safe, and cost-efficient setting that would help analytical workloads with open information codecs and serverless question capabilities.
GOStack provisioned an Amazon S3-based information lake because the central storage layer, offering just about limitless scalability and fine-grained value management. This storage-compute separation permits groups to decouple ingestion, transformation, and analytics processes, with every element scaling independently utilizing probably the most applicable compute engine.
To determine dataset interoperability and discoverability, the workforce adopted AWS Glue Information Catalog because the unified metadata repository. The catalog shops Iceberg desk definitions and makes schemas accessible throughout providers equivalent to Amazon Athena and Apache Spark workloads on Amazon EMR. Most datasets, each batch and streaming, are registered right here, enabling constant metadata visibility throughout the lakehouse.
The info is saved in Apache Iceberg tables on Amazon S3, chosen for its open desk format, ACID transaction help, and highly effective schema evolution options. Yggdrasil required ACID transactions for constant monetary reporting and fraud detection, schema evolution to accommodate quickly altering gaming information fashions, and time journey queries to align with regulatory audit necessities.
GOStack constructed a customized schema conversion and desk registration service. This inside device converts source-system Avro schemas into Iceberg desk definitions and manages the creation and evolution of raw-layer tables. By controlling schema translation and desk registration immediately, the workforce makes certain that metadata stays per the supply programs and supplies predictable, versioned schema evolution aligned with ingestion wants.
The preliminary setup made the next elements:
- Amazon S3 bucket construction design: Applied a multi-layer format (uncooked, curated, and analytics zones) aligned with information lifecycle finest practices.
- AWS Glue Information Catalog integration: Outlined database and desk schemas with partitioning methods optimized for Athena efficiency.
- Iceberg configuration: Enabled versioning and metadata retention insurance policies to stability storage effectivity and question flexibility.
- Safety and compliance: Configured encryption at relaxation utilizing AWS Key Administration Service (AWS KMS), helped implement entry controls by way of AWS IAM and Lake Formation, and applied Amazon S3 bucket insurance policies following the precept of least privilege.
The redesign of the earlier GCP setup helped ship price-performance enhancements. Yggdrasil decreased ingestion and processing prices by roughly 60% whereas additionally reducing operational overhead by means of a extra direct, event-driven pipeline.
Implement real-time information ingestion
After establishing the lakehouse structure, the following step targeted on enabling real-time information ingestion from Yggdrasil’s operational databases into the uncooked information layer of the lakehouse. The target was to seize and ship transactional adjustments as they happen, ensuring that downstream analytics and reporting replicate probably the most up-to-date data.
To attain this, GOStack deployed Debezium Server Iceberg, an open-source challenge that integrates change information seize (CDC) immediately with Apache Iceberg tables. It was deployed as Argo CD purposes on Amazon EKS and used Argo’s GitOps-based mannequin for reproducibility, scalability, and seamless rollouts.
This structure supplies an environment friendly ingestion pathway – streaming information adjustments immediately from the supply system’s outbox tables into the Apache Iceberg tables registered within the AWS Glue Information Catalog and bodily saved on Amazon S3, bypassing the necessity for intermediate brokers or staging providers. By writing information within the Iceberg desk format, the ingestion layer maintained transactional ensures and quick question availability by means of Amazon Athena.
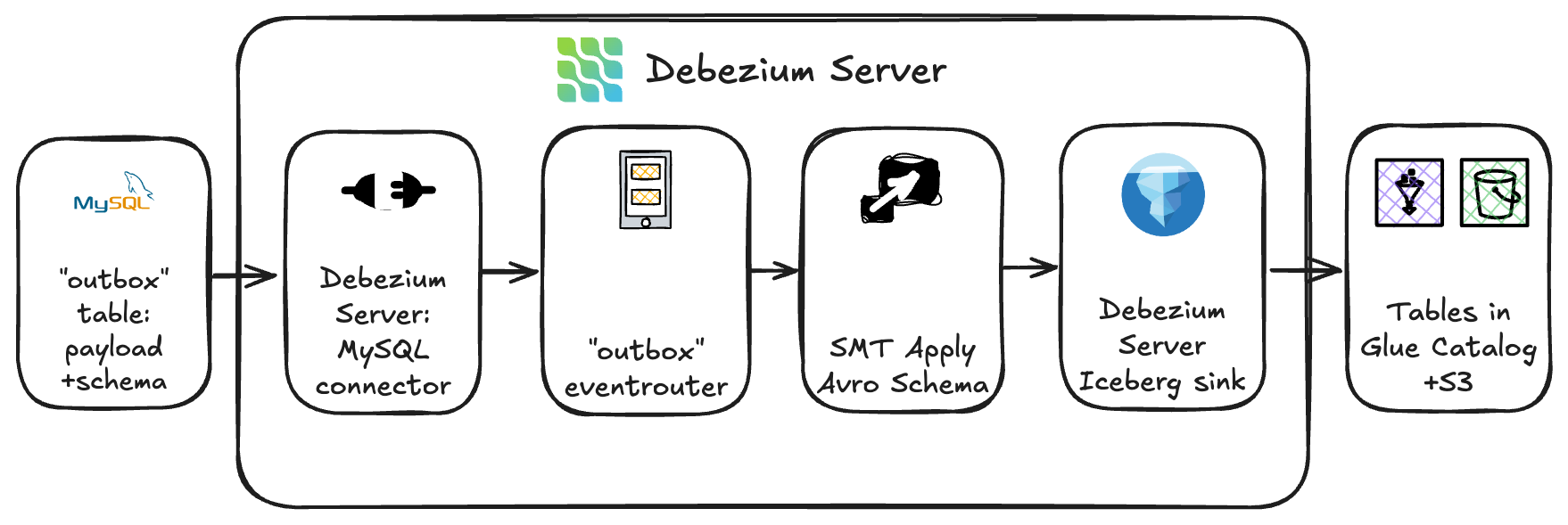
As a result of Yggdrasil’s supply programs emitted outbox occasions containing Avro information, the workforce applied a customized outbox-to-Avro transformation inside Debezium. The outbox desk saved two key elements:
- The Avro schema definition
- The JSON-encoded payload of every file
The customized transformation module mixed these parts into legitimate Avro information earlier than persisting them into the goal Iceberg tables. This method preserved schema constancy and verified compatibility with downstream processing instruments.
To dynamically route incoming change occasions, the workforce leveraged Debezium’s occasion router configuration. Every file was routed to the suitable Apache Iceberg desk (backed by Amazon S3) primarily based on matter and metadata guidelines, whereas desk schemas and partitioning have been ruled on the AWS Glue aspect to take care of stability and alignment with the lakehouse’s information group requirements.
This setup helped ship low-latency ingestion with end-to-end streaming from database outbox to S3-based Iceberg tables in close to actual time. The workforce managed operations finish to finish on Amazon EKS utilizing Helm charts deployed by way of Argo CD in a GitOps mannequin for absolutely declarative, version-controlled operations. ACID-compliant Iceberg writes verified that partially written information couldn’t corrupt downstream analytics. The modular transformation logic allowed future growth to new supply programs or occasion codecs with out rearchitecting the ingestion pipeline.
This Debezium Server resolution supplies quick, real-time information ingestion. GOStack considers it an interim structure. In the long run, the ingestion pipeline will evolve to make use of Amazon Managed Streaming for Apache Kafka (Amazon MSK) because the central occasion spine. Debezium connectors will act as producers, publishing change occasions to Apache Kafka matters, whereas Apache Flink purposes will devour, course of, and write information into Iceberg tables.
This deliberate evolution towards a Kafka-based streaming structure verifies Yggdrasil’s lakehouse stays not solely scalable and cost-efficient immediately, but in addition future-ready – able to supporting richer streaming analytics and broader information integration eventualities because the group grows.
Migrate processing pipelines
As soon as real-time information ingestion was established, GOStack turned its focus to modernizing the information transformation layer. The purpose was to simplify the transformation logic, cut back operational overhead, and unify the orchestration of analytical workloads throughout the new AWS-based lakehouse.
GOStack adopted a lift-and-shift method for a few of Yggdrasil’s information pipelines to help a quick and low-risk transition away from GCP. The light-weight Cloud Run features that beforehand dealt with extraction duties – pulling information from file shares, SharePoint, Google Sheets, and varied third-party APIs – have been re-implemented utilizing AWS Lambda. These Lambda features now combine with the identical exterior programs and write information immediately into Iceberg tables.
For extra complicated processing, earlier Apache Spark purposes operating on Dataproc have been migrated to Amazon EMR with minimal code adjustments. This allowed it to protect the present transformation logic whereas benefiting from the managed scaling capabilities of EMR and improved value management on AWS.
Over time, these processes will probably be regularly refactored and consolidated into containerized workflows on the EKS cluster, absolutely orchestrated by Argo Workflows. This phased migration permits Yggdrasil to maneuver workloads to AWS rapidly and decommission GCP sources sooner, whereas nonetheless leaving room for steady enchancment and modernization of the information system over time.
Lastly, numerous analytical transformations that beforehand lived as BigQuery saved procedures and scheduled queries, that have been now rebuilt as modular dbt fashions executed with dbt-athena. This shift made transformation logic extra clear, maintainable, and version-controlled, enhancing each developer expertise and long-term governance.
Modernizing the transformation layer
With the ingestion pipelines migrated to AWS, GOStack turned its focus to simplifying and modernizing Yggdrasil’s analytical transformations. Reasonably than replicating the earlier stored-procedure–pushed method, the workforce rebuilt the transformation layer utilizing dbt to assist enhance maintainability, lineage visibility, orchestration, and long-term governance.As a part of this redesign, a number of information fashions have been reshaped to suit the brand new lakehouse structure. Probably the most important effort concerned rewriting a vital Spark-based monetary transformation right into a set of SQL-driven dbt fashions. This shift not solely aligned the logic with the lakehouse design but in addition eliminated the necessity for long-running Spark clusters, serving to generate operational and price financial savings.For the curated information layers, changing the legacy warehouse, GOStack consolidated quite a few scheduled queries and saved procedures into structured dbt fashions. This supplies standardized, version-controlled transformations and clear lineage throughout the analytical stack.
Orchestration was simplified as effectively. Beforehand, coordination was cut up between Apache Airflow for Spark workloads and scheduled queries analytical transformations, creating operational friction and dependency dangers. Within the new structure, Argo Workflows on Amazon EKS orchestrates dbt fashions centrally, consolidating the transformation logic inside a single workflow engine. Whereas most transformations nonetheless run on time-based schedules immediately, the system now helps event-driven execution by means of Argo Occasions, giving the chance to progressively undertake trigger-based workflows because the transformation layer evolves.
This unified orchestration framework can carry a number of advantages:
- Consistency: One orchestration layer for information workflows throughout ingestion and transformation.
- Automation: Occasion-driven dbt runs assist take away guide scheduling and cut back operational overhead.
- Scalability: Argo Workflows scales with the EKS cluster, dealing with concurrent dbt jobs seamlessly.
- Observability: Centralized logging and workflow visualization assist enhance visibility into job dependencies and information freshness.
By way of this transformation, Yggdrasil efficiently unified its information lakes and warehouses into a contemporary lakehouse structure, powered by open information codecs, serverless question engines, and modular transformation logic. The transfer to dbt and Athena not solely simplified operations but in addition helped pave the best way for sooner iteration, easier governance, and larger developer productiveness throughout the information setting.
Lakehouse efficiency optimizations
Whereas efficiency tuning is an ongoing journey, as a part of the transformation redesign, GOStack made few performance-oriented tweaks to ensure Athena queries could be quick and cost-efficient. The Apache Iceberg tables have been saved in Parquet with ZSTD compression, offering sturdy learn efficiency and lowering the quantity of information scanned by Athena.
Partitioning methods have been additionally aligned to precise entry patterns utilizing Iceberg’s native partitioning. Uncooked information zones have been partitioned by ingestion timestamp, enabling environment friendly incremental processing. Curated information used business-driven partition keys, equivalent to participant or recreation identifiers and date dimensions, to assist optimize analytical queries. These designs made certain Athena may prune unneeded information and constantly scan solely the related partitions.
Iceberg’s native partitioning options, together with transforms equivalent to bucketing and time slicing, exchange conventional Hive partitioning patterns. As a result of Iceberg manages partitions internally in its metadata layer, not all Glue or Athena partition constructs apply. Counting on Iceberg’s native partitioning helps present predictable pruning and constant efficiency throughout the lakehouse with out introducing legacy Hive behaviors.
To deal with the excessive quantity of small recordsdata produced by real-time ingestion, GOStack enabled AWS Glue Iceberg compaction. This robotically merges small Parquet recordsdata into bigger segments, serving to enhance question efficiency and cut back metadata overhead with out guide intervention.
Allow governance
The workforce adopted AWS Lake Formation as the first governance layer for the curated zone of the lakehouse, leveraging Lake Formation hybrid entry mode to handle fine-grained permissions alongside present IAM-based entry patterns. This hybrid mode supplies an incremental and versatile pathway to undertake Lake Formation with out forcing a full migration of legacy permissions or inside pipeline roles, making it a perfect match for Yggdrasil’s phased modernization technique.
Lake Formation gives centralized authorization, supporting database, desk, column, and, critically for Yggdrasil, row-level permissions. These capabilities are important due to the corporate’s multi-tenant working mannequin:
- Sport improvement companions require entry to information and reviews pertaining solely to their very own video games, facilitating each safety and compliance alignment with accomplice agreements.
- iGaming operators integrating with Yggdrasil’s system should obtain operational and monetary insights completely for their very own information, enforced robotically by means of reporting instruments backed by curated Iceberg tables.
With Lake Formation hybrid entry mode, tenant-specific row-level entry insurance policies are constantly enforced throughout Amazon Athena, AWS Glue, and Amazon EMR, with out introducing breaking adjustments to present IAM-based workloads. This allowed Yggdrasil to implement sturdy governance for exterior customers whereas preserving inside operations secure and predictable.
Internally, Lake Formation can also be used to grant the Analytics workforce and BI instruments focused entry to curated datasets, easy however centrally managed to take care of consistency and cut back administrative overhead.
For ingestion and transformation workloads, the workforce continues to depend on IAM roles and insurance policies. Companies equivalent to Debezium, dbt, and Argo Workflows require broad however managed entry to uncooked and intermediate storage layers, and IAM supplies a simple, least-privilege mechanism for granting these permissions with out involving Lake Formation within the inside pipeline path.
By adopting Lake Formation in hybrid entry mode and mixing it with IAM for inside providers, Yggdrasil established a governance mannequin that may stability sturdy safety with operational flexibility – enabling the lakehouse to scale securely because the enterprise grows.
Outcomes and enterprise influence
The brand new lakehouse, constructed on Amazon Athena, Amazon S3, and AWS Glue Information Catalog, now underpins superior analytics and AI/ML use instances equivalent to participant conduct modeling, predictive recreation suggestions, and fraud detection.
The optimized lakehouse design permits Yggdrasil to quickly onboard new analytics workloads and enterprise use instances, serving to ship measurable outcomes:
- Decreased operational complexity by means of consolidation on AWS analytics providers
- Value optimization with a 60% discount in information processing prices
- Improved information freshness with 75% decrease latency for analytics outcomes (from 2 hours to half-hour)
- Enhanced governance utilizing the AWS Lake Formation fine-grained controls
- Future-ready structure leveraging open codecs and serverless analytics
Conclusion
Yggdrasil Gaming’s migration journey illustrates how organizations can efficiently transition from proprietary analytics programs to an open, versatile lakehouse structure. By following a phased method guided by AWS Effectively-Architected Framework rules, Yggdrasil maintained enterprise continuity whereas establishing a contemporary basis for his or her information wants.
Based mostly on this expertise, a number of classes emerged to assist information your personal transfer to an AWS-based lakehouse:
- Assess your present state: Establish ache factors in your present information structure and set up clear targets for modernization.
- Begin small: Start with a pilot challenge utilizing AWS analytics providers to validate the lakehouse method to your particular use instances.
- Design for openness: Leverage open desk codecs like Apache Iceberg to take care of flexibility and keep away from vendor lock-in.
- Implement regularly: Comply with a phased migration technique just like Yggdrasil’s, prioritizing high-value workloads.
- Optimize repeatedly: Use efficiency tuning strategies for Amazon Athena to assist maximize effectivity and reduce prices.
To study extra about constructing trendy lakehouse architectures, discuss with “The lakehouse structure of Amazon SageMaker”.
Concerning the authors