

{kind=link}
One of the best LLM for Coders is again with some new skills. Anthropic lately launched Claude Sonnet 4.5, a robust addition to its suite of LLMs. This new launch considerably boosts capabilities, particularly for duties requiring superior Agentic AI. It exhibits marked enhancements in areas like code era and multimodal reasoning, setting new requirements for effectivity and reliability. The mannequin guarantees a leap in efficiency throughout numerous benchmarks. This deep dive explores all elements of this vital growth.
Key Options of Claude Sonnet 4.5
Claude Sonnet 4.5 represents a strategic development for Anthropic. It combines excessive efficiency with enhanced security protocols. This mannequin targets complicated duties that demand a nuanced understanding. It gives a compelling steadiness of velocity, price, and intelligence for a lot of purposes.
Sonnet 4.5 is state-of-the-art on the SWE-bench Verified analysis, which measures real-world software program coding skills. Virtually talking, we’ve noticed it sustaining focus for greater than 30 hours on complicated, multi-step duties.
- Efficiency Overview: Anthropic designed Sonnet 4.5 for superior efficiency. It excels in numerous benchmarks. These embody software program engineering and monetary evaluation. The mannequin gives constant and correct outputs. Its capabilities prolong past easy responses.
- Effectivity and Velocity: The brand new Sonnet 4.5 delivers quicker processing. It maintains high-quality outputs. This effectivity makes it appropriate for real-time purposes. Customers profit from faster process completion. This results in improved productiveness in numerous workflows.
- Context Window: Sonnet 4.5 includes a strong context window. This permits it to deal with giant inputs. It processes intensive textual content and code successfully. The expanded context helps keep coherence in lengthy interactions. This characteristic is essential for complicated initiatives.
- Multimodality: Claude Sonnet 4.5 helps numerous enter varieties. It processes each textual content and picture knowledge. This multimodal reasoning permits a richer understanding. It permits for extra versatile purposes. This adaptability is essential for contemporary AI programs.
Efficiency Benchmarks and Comparisons
Claude Sonnet 4.5 underwent rigorous testing. Its efficiency stands out towards rivals. Benchmarks present its energy in numerous domains. These outcomes spotlight its superior capabilities.
Agentic Capabilities
Sonnet 4.5 exhibits main efficiency in agentic duties. On the SWE-bench, it achieved 77.2% verified accuracy. This rises to 82.0% with parallel test-time computation. This surpasses Claude Opus 4.1 (74.5%) and GPT-5 Codex (74.5%). Its energy in code era is evident. For agentic terminal coding (Terminal-Bench), Sonnet 4.5 scored 50.0%. This leads all different fashions, together with Opus 4.1 (46.5%). In agentic software use (t2-bench), Sonnet 4.5 scored 70.0% for airline duties. It achieved a powerful 98.0% for telecom duties. This demonstrates its sensible utility for Agentic AI workflows. The mannequin additionally scored 61.4% on OSWorld for pc use. This leads Opus 4.1 (44.4%) considerably.
Reasoning and Math
Sonnet 4.5 exhibits sturdy reasoning expertise. It scored 100% on highschool math issues. These issues had been from AIME 2025 utilizing Python. This final result highlights its exact mathematical skills. For graduate-level reasoning (GPQA Diamond), it achieved 83.4%. This locations it among the many prime LLMs.
Multilingual and Visible Reasoning
In Multilingual Q&A (MMMLU), Sonnet 4.5 achieved 89.1%. This exhibits its world language comprehension. Its visible reasoning (MMMU validation) rating was 77.8%. This functionality helps numerous knowledge inputs. This strengthens its multimodal reasoning.
STEM Evaluation
Sonnet 4.5 pondering excels in monetary duties. It achieved 69% on the STEM benchmark. This efficiency surpasses Opus 4.1 pondering (62%) and GPT-5 (46.9%). This means its worth for specialised monetary evaluation.
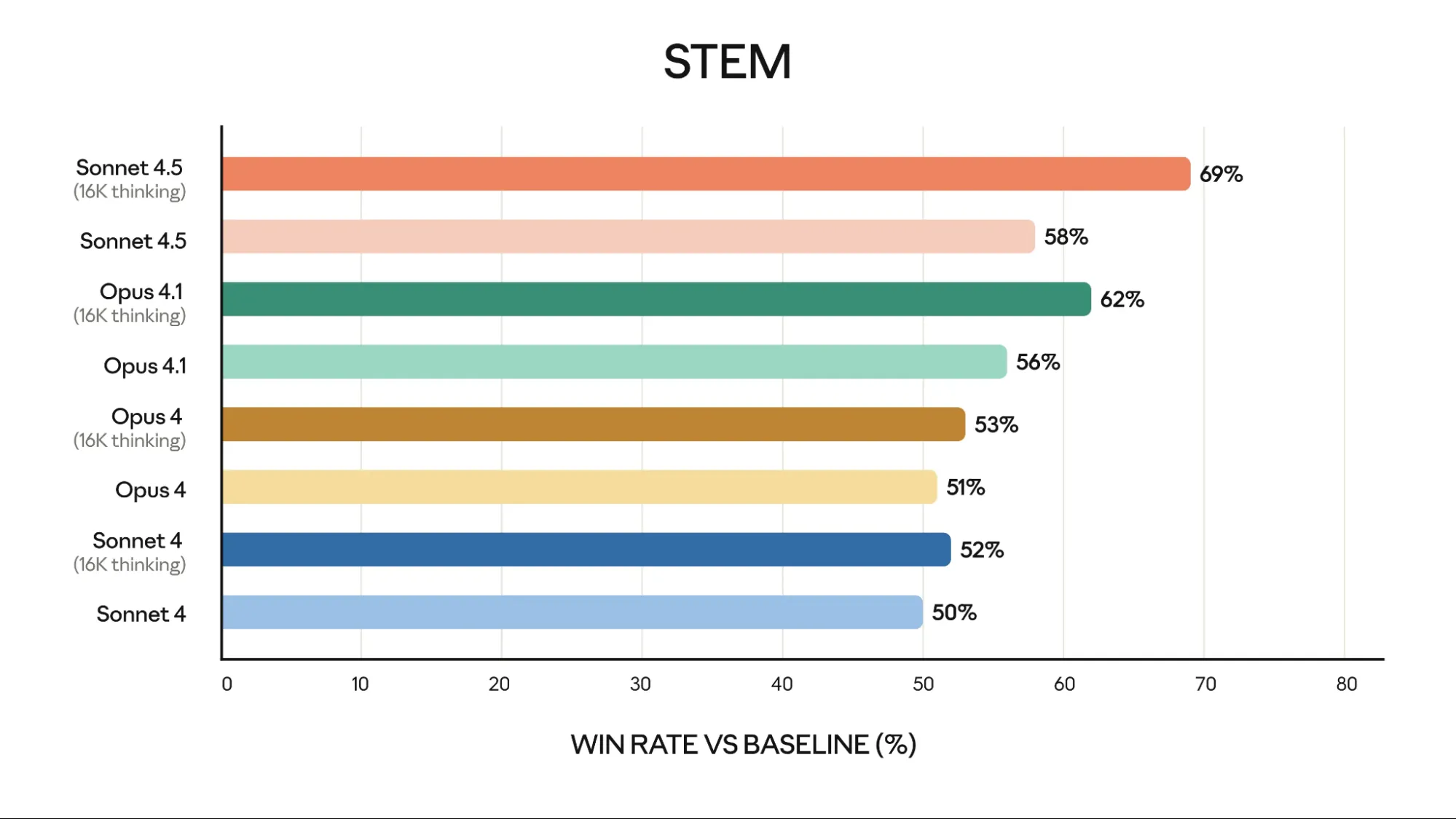
Additionally, Claude Sonnet 4.5 excels in finance, legislation, medication, and STEM. It exhibits Claude Sonnet 4.5 dramatically has higher domain-specific data and reasoning in comparison with older fashions, together with Opus 4.1.
Security and Alignment
Anthropic prioritizes security in its LLMs. Claude Sonnet 4.5 exhibits low misaligned habits scores. It scored roughly 13.5% in simulated settings. That is notably decrease than GPT-4o (~42%) and Gemini 2.5 Professional (~42-43%). This concentrate on security makes Claude Sonnet 4.5 a dependable choice. Anthropic’s analysis ensures safer interactions.
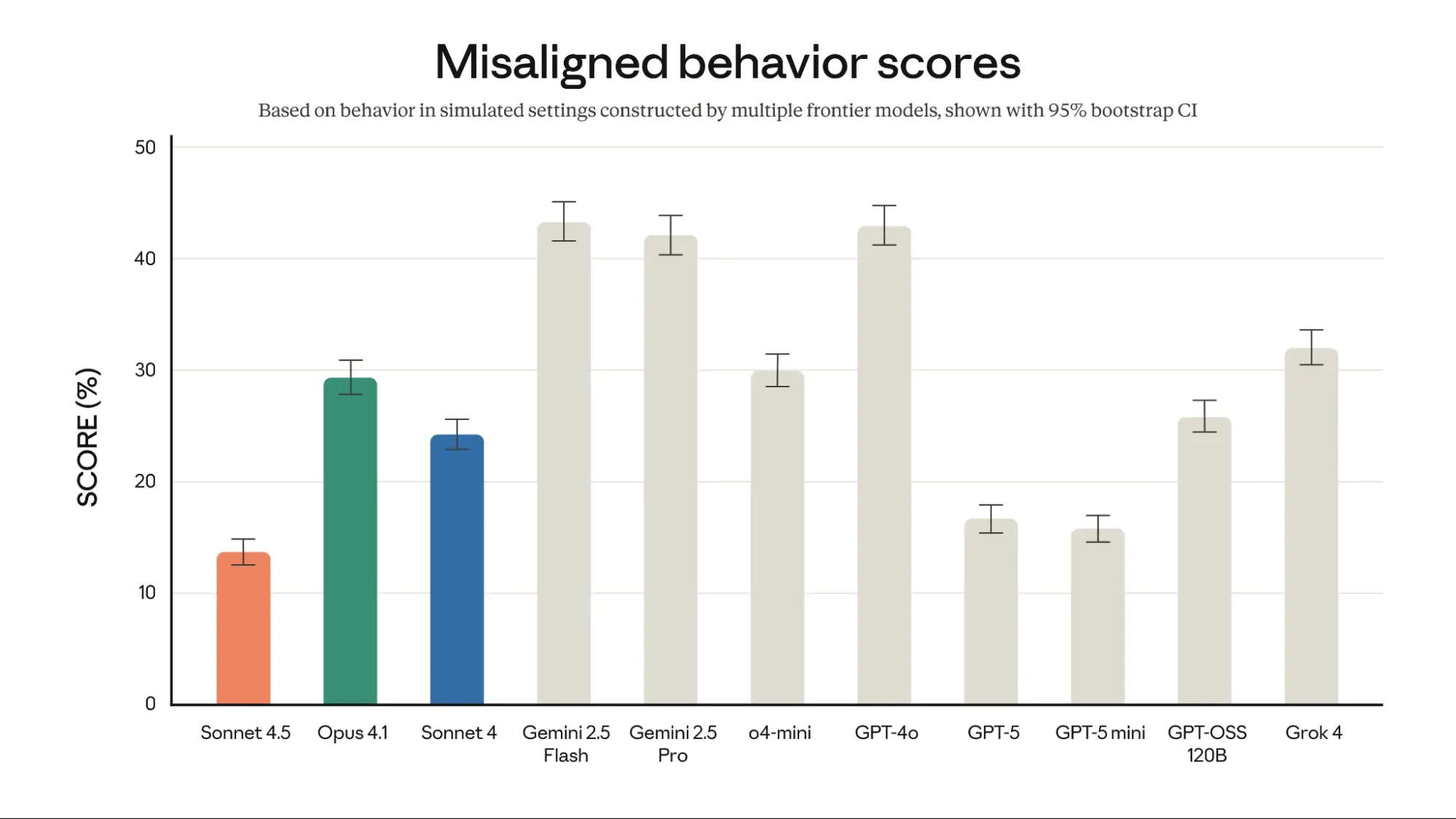
General misaligned habits scores from an automatic behavioral auditor (decrease is best). Misaligned behaviors embody (however should not restricted to) deception, sycophancy, power-seeking, encouragement of delusions, and compliance with dangerous system prompts.
Accessing Claude Sonnet 4.5
Builders can entry Sonnet 4.5 instantly. It’s out there via Anthropic’s API. Merely use claude-sonnet-4-5 through the Claude API. Pricing stays the identical as Claude Sonnet 4, at $3-$15 per million tokens.
pip set up anthropic
import anthropic
# Initialize the Anthropic shopper utilizing the API key out of your setting variables.
shopper = anthropic.Anthropic()
def get_claude_response(immediate: str) -> str:
"""
Sends a immediate to the Claude Sonnet 4.5 mannequin and returns the response.
"""
attempt:
response = shopper.messages.create(
mannequin="claude-sonnet-4-5-20250929", # Use the newest mannequin ID
max_tokens=1024,
messages=[
{"role": "user", "content": prompt}
]
)
# Extract and return the content material of the response.
return response.content material[0].textual content
besides Exception as e:
return f"An error occurred: {e}"
# Instance utilization
user_prompt = "Clarify the idea of quantum computing in easy phrases."
claude_response = get_claude_response(user_prompt)
print(f"Claude's response:n{claude_response}")Customers may entry it through the developer console. Numerous partnering platforms can even supply entry. These embody Amazon Bedrock and Google Cloud Vertex AI. The mannequin goals for broad accessibility. This helps numerous growth wants.
There’s additionally a restricted, free model of Sonnet 4.5 out there to the general public. The free model is meant for basic use and has vital utilization restrictions in comparison with paid plans. The Session-based limitations reset each 5 hours. As an alternative of a hard and fast each day message depend, your restrict is dependent upon the complexity of your interactions and present demand.
Go to Claude, and you’ll attempt Sonnet 4.5 at no cost.
Arms-on Duties: Testing Claude Sonnet 4.5’s Talents
Testing Claude Sonnet 4.5 with particular duties reveals its energy. These examples spotlight its strengths. They showcase their superior reasoning and code era.
Job 1: Multimodal Monetary Development Evaluation
This process combines visible knowledge interpretation with deep textual evaluation. It showcases Claude Sonnet 4.5’s multimodal reasoning. It additionally highlights its particular strengths in monetary evaluation.
Immediate: “Analyze the connected bar chart picture. Establish the general income pattern. Pinpoint any vital drops or spikes. Clarify potential financial or market components behind these actions. Assume entry to basic market data as much as October 2023. Generate a bullet-point abstract. Then, create a quick, persuasive e-mail to stakeholders. The e-mail ought to define key findings and strategic suggestions.”
Output:

Claude Sonnet 4.5 demonstrates its multimodal reasoning right here. It processes visible data from a chart. Then it integrates this with its data base. The duty requires monetary evaluation to clarify market components. Producing a abstract and an e-mail exams its communication model. This exhibits its sensible utility.
Job 2: Hexagon with Gravity Simulation
Immediate: “In a single HTML file, create a simulation of 20 balls (they comply with the principles of gravity and physics) which begin within the heart of a spinning 2D hexagon. Gravity ought to change from the underside to the highest each 5 seconds.”
Output:
You’ll be able to entry the deployed HTML file right here: Claude
Claude Sonnet 4.5 demonstrates its multimodal reasoning right here. It processes visible data from a chart. Then it integrates this with its data base. The duty requires monetary evaluation to clarify market components. Producing a abstract and an e-mail exams its communication model. This exhibits its sensible utility.
It exhibits Sonnet 4.5’s capabilities to deal with complicated multi-task prompts over an prolonged horizon. It exhibits the mannequin’s reasoning because it simulated the gravity contained in the 2D Hexagon. The generated HTML is error-free, and the hexagon is rendered within the first iteration solely.
My Opinion
Claude Sonnet 4.5 gives sturdy agentic capabilities which can be a robust but protected choice for builders. The mannequin’s effectivity and multimodal reasoning improve AI purposes. This launch underscores Anthropic’s dedication to accountable AI. It gives a strong software for complicated issues. Claude Sonnet 4.5 units a excessive bar for future LLMs. As we all know, Claude at all times focuses extra on the coders, based mostly on the clear benefit their fashions had in coding-related duties in distinction to their contemporaries. This time, they’ve elevated their particular area data skills like Legislation, Finance, and Medication.
Conclusion
Claude Sonnet 4.5 marks a notable development in Agentic AI. It gives enhanced code era and multimodal reasoning. Its sturdy efficiency throughout benchmarks is evident. The mannequin additionally options superior security. Builders can combine this highly effective LLM at present. Claude Sonnet 4.5 is a dependable resolution for superior AI challenges.
Regularly Requested Questions
A. Claude Sonnet 4.5 options enhanced agentic capabilities, higher code era, and improved multimodal reasoning. It gives a robust steadiness of efficiency and security.
A. It exhibits main efficiency in SWE-bench and Terminal-Bench. This consists of 82.0% on SWE-bench with parallel test-time compute, surpassing many rivals.
A. Sure, it achieved a 100% rating on highschool math competitors issues (AIME 2025). This exhibits exact mathematical and reasoning skills.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Enthusiastic about GenAI, NLP, and making machines smarter (in order that they don’t substitute him simply but). When not optimizing fashions, he’s in all probability optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.