

October 11, 2024
As extra proof involves gentle, it turns into clear that Google’s monopolistic conduct isn’t restricted to its dominance in search. The corporate is leveraging its browser, its huge person base, and the info it collects to remain forward in AI improvement, advert focusing on, and search, making certain that no competitor can catch up. The various coincidences surrounding the launch and outcomes of Cell-First Indexing paint a regarding image of Google’s operations, particularly when seen underneath the brand new urged lens of Chrome as a possible distributed computing system. The corporate’s near-total dominance within the browser market permits it to gather unprecedented quantities of knowledge from unsuspecting customers, whereas utilizing that information to construct stronger promoting fashions, prepare AI together with advert modeling, like what’s used for PMAX, all to additional entrench its monopoly.
https://youtu.be/txNT1S28U3M?si=r-NV7bHtr_4nvGTm&t=2006

That is the third and last article in a three-part sequence a couple of potential new understanding of how Google is likely to be getting details about pages once they crawl. The primary article outlined the primary assumptions and understandings that underlie the search engine optimization neighborhood’s interactions with Google, particularly associated to crawling, rendering, Indexing and rating. The second article within the sequence reviewed particulars of the brand new idea, particularly about how the second section of Google’s Cell-First Indexing is likely to be working. This final article will overview the potential implications of this new understanding, the way it might be examined and verified, and what Google may do to make clear the state of affairs.
Google’s affect extends far past the search engine and even internet advertising worlds. By amassing and modeling person information, and by doubtlessly turning Chrome right into a device for rendering and information processing, Google has primarily turned the vast majority of web customers into unwitting members of their monopolistic enterprise practices. We all know that every one the info that Google collects could be shared throughout all of Google’s properties – it’s a part of their Phrases and Situations, so Chrome information is actually getting used to create detailed fashions of person conduct and buy conduct (Journeys and Journey modeling) utilized in Google Uncover, Google Adverts and Google Search, and which Google leverages for the whole lot from categorizing customers into quite a lot of completely different cohorts to raised goal advertisements and doubtlessly additional prepare AI.
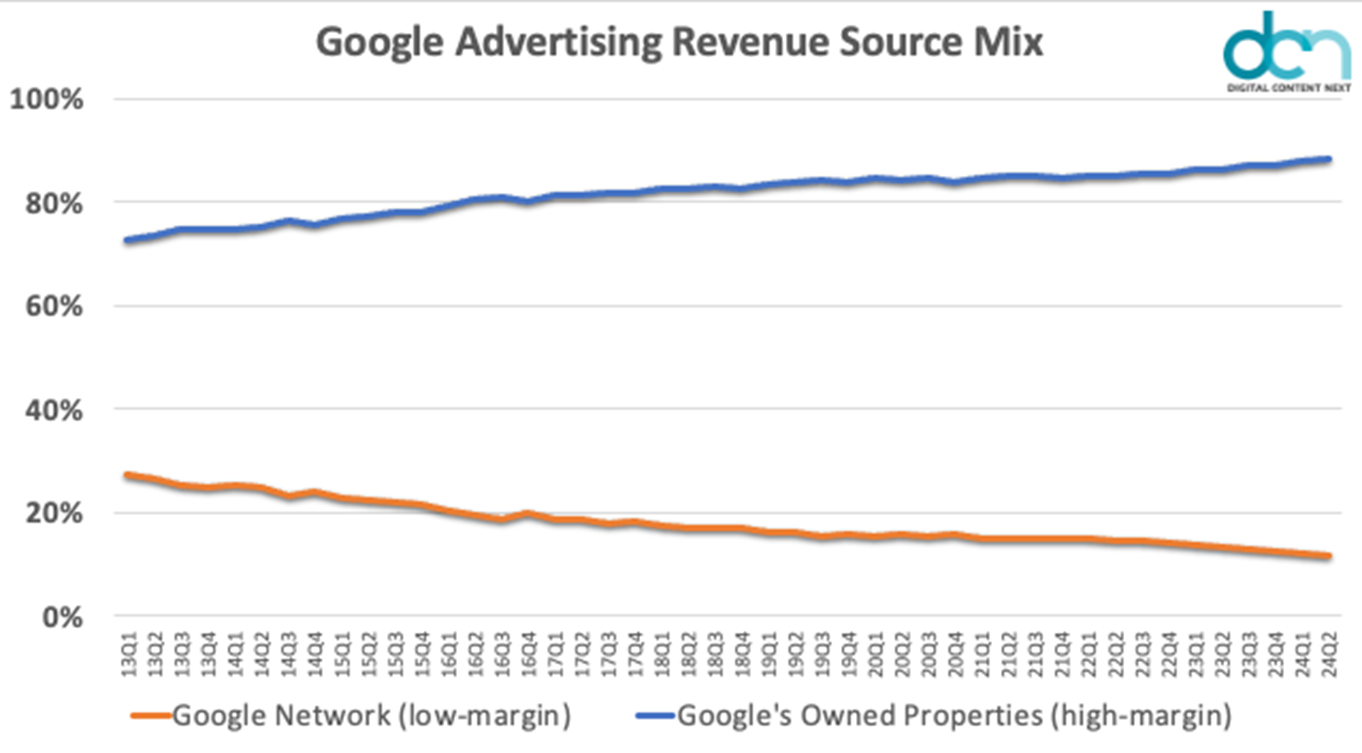
Google’s skill to harness information from billions of customers by means of Chrome isn’t nearly bettering advert focusing on or search algorithms. There’s rising concern that Google can be utilizing this information to take natural clicks and ship extra clicks to paid advertisements – to be able to instantly feed their bottom-line and please anxious buyers. The price of AI processing is excessive, and Google desires to have the ability to compete; the intentional undercutting of aggressive advert networks and low-margin advert fashions could also be half of a bigger plan that Google must fund its AI improvement efforts.
The issue is, this seems to be at the price of small publishers who beforehand made their residing with web sites that ranked nicely and drove natural visitors, then in a single day, misplaced the whole lot in one of many Useful Content material Updates. Whereas it’s Google’s proper to alter their algorithm at will, it’s not their proper to rob content material creators by lifting their content material into an AI Overview, and displaying it with out attribution and/or not even displaying web sites when they’re looked for by title, when the one justification is that Google didn’t approve or profit sufficient from their chosen technique of monetization.
https://x.com/jason_kint/standing/1834801152254246919/photograph/1
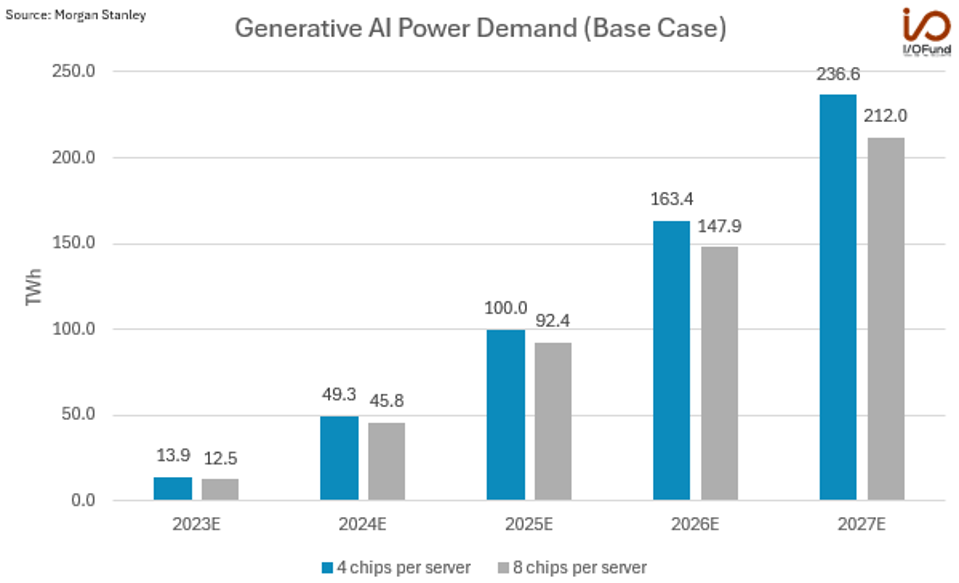
This example is very regarding in gentle of the continued monetary losses and useful resource challenges confronted by different AI corporations like OpenAI. Google, with its distributed processing mannequin, might have discovered a option to sidestep these challenges, giving it an unassailable benefit within the AI area. Google already affords distributed and hybrid cloud options for his or her Google Cloud enterprise shoppers. Why do we expect that they aren’t leveraging learnings from these ventures to make sure their AI processing capabilities into the long run. Google is staffed by the neatest technologists on the earth, and if I can see this as a possible answer, so can they – and so they in all probability did years in the past. And whether or not witting or unwitting, the transition from Common Google Analytics to the far inferior Google Analytics 4, and the deletion of terabytes of historic information for websites that didn’t correctly transition additionally appears suspicious right here.
A Name for Transparency About Chrome Information
The time has come for larger scrutiny of Google’s practices. As SEOs, digital entrepreneurs, and web customers, we have to cease blindly accepting Google’s explanations and begin questioning the extent of its affect. Google’s management over information assortment, search rankings, and promoting is not only a matter of market dominance — it’s a matter of moral concern. Through the use of our private units as a part of their information assortment and processing community, Google is overstepping boundaries in ways in which may have far-reaching penalties for privateness, competitors, and the way forward for AI.
Because the demand for compute and processing energy grows almost exponentially, and with the expansion of pricy and as-yet unprofitable AI processing programs, Google could also be pushed to broaden its use of distributed computing in Chrome even additional. It’s time to demand transparency and accountability from Google earlier than their unchecked energy results in even larger monopolistic management over the web. Customers need to know what information is being collected and the way it’s getting used and regulators should act to restrict Google’s stranglehold on the digital world earlier than it’s too late.
This idea, and even the chance that it’s true and inflicting hurt, ought to function a wake-up name for regulators, business leaders, and customers alike. Google’s secret use of Chrome as a knowledge assortment device is extra than simply unethical; it’s abusive and doubtlessly unlawful. It’s time for critical motion to be taken. In essence, Google has weaponized Chrome’s huge market share to collect information from over 65% of the world’s web customers with out most of them realizing it.
Particular Notes for These Who Need to Delve Deeper:
Whereas the big majority of suggestions on this idea has been enthusiastic, the primary criticism has been that there are too many logical leaps, and that “huge theories require huge proof.” I don’t disagree in any respect that the speculation has not been 100% confirmed in my speak or on this article sequence. Whereas there’s a number of fascinating circumstantial proof offered, some have requested extra particulars about telemetry logs and packets the place the Chrome information is being despatched. Others have urged that the information can be too huge to go unnoticed, and that this could be such an invasive observe that no firm would permit Chrome for use by workers – particularly to entry delicate company information, plans or data.
The concept that Google is capturing data from Chrome just isn’t new – the primary time that I can discover in our business that this idea was put forth was 2011, when GoogleBot first began crawling with MediaKit; So this isn’t new however folks do nonetheless appear to battle with the idea that Google might not have defined or gotten specific permission for the whole lot that they’re amassing, and the issues that they’re utilizing it for.
We must always not assume that Google is performing in good religion by default. Possibly Google classifies all of this information seize within the broad language of their Phrases and Situations, the place all of us agree that information can be utilized to ‘enhance search high quality’, or another overly-broad designation. Possibly Google has developed a brand new, proprietary know-how that they’re utilizing to compress or cover the info switch in covertly put in extensions, person account administration programs, video calls in Meet, weekly Chrome updates or different widespread person behaviors. Assuming that we learn about all the applied sciences and strategies which can be being utilized by Google appears a bit naive. And Chrome just isn’t the one downside; On Android telephones, Google has direct entry to much more information by means of the OS, and could also be transferring information out of Chrome telemetry, to move it underneath completely different labels.
What we all know for certain is that Chrome is already amassing web page rendering information, if not the complete web page rendering for CrUX and Core Net Vitals, and that they’re amassing page-level interactions of actual customers – all with out specific consent exterior of customers accepting the traditional Phrases and Situations. Google stipulates all of this – so the concept that the complete web page rendering can also be captured is basically not that a lot of a stretch in my thoughts. Some have famous that any sort of personalization, cookies or extensions would trigger issues with the rendered web page, however Google will get a stateless browser expertise in Section 1 of crawling, so they need to have the ability to use this to check and determine when pages have been modified. Past this, permissions need to be given on to Chrome for a browser extension to change the viewing expertise on a web page, so Chrome may simply omit these pages from their dataset.
The default settings in Chrome permit for quite a lot of various kinds of information assortment, and describe it as periodic, so not on a regular basis, which would definitely make it tougher to seek out and consider. We’ve additionally realized from safety specialists that the info that Chrome sends to person accounts is closely encrypted, and never potential for anybody with out the mandatory decryption instruments to determine – so once more, we simply don’t know what information Chrome is sending.

Google might be pre-processing data in order that it’s smaller and fewer prone to be detected, relatively than sending the totally rendered web page. They might be solely requesting and receiving web page information sporadically, on an as-needed foundation, after section 1 of a crawl has been accomplished. They might be sending information of pages with sufficient visits to the CrUX system to be anonymized and processed for Core Net Vitals earlier than it’s despatched on to be used within the index. The information might be streamed by means of a but unknown extension or API that Google has baked into the code, into the person admin performance or into any variety of different parts that we take without any consideration when utilizing Chrome. The reality is, Google is filled with intelligent builders who wish to make the net higher. In the event that they consider that what they’re constructing into Chrome is doing that they won’t query it. We all know Google has a historical past of gifted engineers leaving the group once they get scared with how the enormous is utilizing the tech that they helped to construct.
I’m eagerly hoping that this text and the speak that it’s primarily based on will encourage folks extra technical than me to start out trying extra deeply into precisely what Chrome is doing with our computer systems and telephones. Even when issues and warnings aren’t 100% provable, they carry gentle to matters which can be worthy of consideration, and they’re necessary work when nobody else is prepared to come back ahead with their issues. Already one particular person – Mark Williams-Cook dinner – has arrange a take a look at to see if we will show the speculation out, and I hope others will arrange their very own exams too.
At a minimal, we all know that Google’s new Pixel 9XL telephones are transmitting personal information as typically as each quarter-hour. In response to the Tweaktown article,“… the system is robotically connecting to system administration and coverage enforcement endpoints, which suggests Google has distant management capabilities” and all that is occurring whereas Gemini is disabled. Past that, in accordance with Aras Nazarovas, a safety researcher at Cybernews, Google is amassing location even when the GPS location options are turned off, and “the Pixel 9 Professional XL repeatedly makes use of PII for authentication, configuration, and logging. This observe doesn’t align with the business’s greatest anonymization practices and seems extreme.” If that is the lax care that Google has given its most up-to-date, flagship product, it appears seemingly that the oversight and overreach aren’t remoted to simply that one occasion.
Questions that Google Ought to be Anticipated to Reply:
If Google just isn’t doing something described within the article or video, they may merely deny all of it. This appears unlikely, so as a substitute, now we have urged some questions that we expect regulators ought to be asking, and investigators ought to be trying into when evaluating what information is being captured by Chrome.
- What degree of processing, pre-processing or information analysis is occurring on native computer systems and telephones? Is that this one thing a person can decide out of?
- What’s the function of together with TensorFlow Lite code in Chrome? What sort of data is it processing?
- How does Chrome stop web page engagement information, web page expertise information, loading information and Core Net Vitals data from being collected on pages which can be behind firewalls?
- How did personal teams and paperwork develop into listed and ranked by Google’s algorithm in February of 2024? What has been accomplished to stop related issues from occurring once more sooner or later?
- How is private information being anonymized and when is private information getting used to coach Google’s AI? Are there new or evolving safety or privateness measures that we should always learn about?