

{kind=link}
The standard of information used is the cornerstone of any knowledge science challenge. Dangerous high quality of information results in inaccurate fashions, deceptive insights, and expensive enterprise selections. On this complete information, we’ll discover the development of a robust and concise knowledge cleansing and validation pipeline utilizing Python.
What’s a Knowledge Cleansing and Validation Pipeline?
A knowledge cleansing and validation pipeline is an automatic workflow that systematically processes uncooked knowledge to make sure its high quality meets accepted standards earlier than it’s subjected to evaluation. Consider it as a high quality management system on your knowledge:
- Detecting and coping with lacking values – Detects gaps in your dataset and applies an applicable therapy technique
- Validates knowledge sorts and codecs – Makes certain every subject accommodates info of the anticipated kind
- Identifies and removes outliers – Detects outliers which will skew your evaluation
- Enforces enterprise guidelines – Applies domain-specific constraints and validation logic
- Maintains lineage – Tracks what transformations have been made and when
The pipeline primarily acts as a gatekeeper to ensure that solely clear and validated knowledge flows into your analytics and machine studying workflows.
Why Knowledge Cleansing Pipelines?
A number of the key benefits of automated cleansing pipelines are:
- Consistency and Reproducibility: Handbook strategies can introduce human error and inconsistency into the cleansing procedures. Automated pipelining implements the identical cleansing logic again and again, thereby making the outcome reproducible and plausible.
- Time and Useful resource Effectivity: Making ready the info can take between 70-80% of the time of an information scientist. Pipelines automate their knowledge cleansing course of, largely lowering this overhead, channeling the crew in the direction of the evaluation and modeling.
- Scalability: As an illustration, as knowledge volumes develop, guide cleansing turns into untenable. Pipelines optimize the processing of huge datasets and deal with rising knowledge masses nearly robotically.
- Error Discount: Automated validation picks up knowledge high quality points that guide inspection could miss, therefore lowering the danger of drawing incorrect conclusions from falsified knowledge.
- Audit Path: Pipelines in place define for you exactly what steps have been adopted to wash the info, which might be very instrumental in terms of regulatory compliance and debugging.
Setting Up the Improvement Surroundings
Earlier than embarking upon the pipeline constructing, allow us to ensure that now we have all of the instruments. Our pipeline shall benefit from the Python powerhouse libraries:
import pandas as pd
import numpy as np
from datetime import datetime
import logging
from typing import Dict, Record, Any, ElectiveWhy these Libraries?
The next libraries will probably be used within the code, adopted by the utility they supply:
- pandas: Robustly manipulates and analyzes knowledge
- numpy: Offers quick numerical operations and array dealing with
- datetime: Validates and codecs dates and instances
- logging: Allows monitoring of pipeline execution and errors for debugging
- typing: Just about provides kind hints for code documentation and avoidance of widespread errors
Defining the Validation Schema
A validation schema is basically the blueprint defining the expectations of information as to the construction they’re primarily based and the constraints they observe. Our schema is to be outlined as:
VALIDATION_SCHEMA = {
'user_id': {'kind': int, 'required': True, 'min_value': 1},
'e-mail': {'kind': str, 'required': True, 'sample': r'^[^@]+@[^@]+.[^@]+$'},
'age': {'kind': int, 'required': False, 'min_value': 0, 'max_value': 120},
'signup_date': {'kind': 'datetime', 'required': True},
'rating': {'kind': float, 'required': False, 'min_value': 0.0, 'max_value': 100.0}
}The schema specifies quite a lot of validation guidelines:
- Kind validation: Checks the info kind of the acquired worth for each subject
- Required-field validation: Identifies necessary fields that should not be lacking
- Vary validation: Units the minimal and most acceptable type of worth
- Sample validation: Common expressions for validation functions, for instance, legitimate e-mail addresses
- Date validation: Checks whether or not the date subject accommodates legitimate datetime objects
Constructing the Pipeline Class
Our pipeline class will act as an orchestrator that coordinates all operations of cleansing and validation:
class DataCleaningPipeline:
def __init__(self, schema: Dict[str, Any]):
self.schema = schema
self.errors = []
self.cleaned_rows = 0
self.total_rows = 0
# Setup logging
logging.basicConfig(degree=logging.INFO)
self.logger = logging.getLogger(__name__)
def clean_and_validate(self, df: pd.DataFrame) -> pd.DataFrame:
"""Major pipeline orchestrator"""
self.total_rows = len(df)
self.logger.information(f"Beginning pipeline with {self.total_rows} rows")
# Pipeline phases
df = self._handle_missing_values(df)
df = self._validate_data_types(df)
df = self._apply_constraints(df)
df = self._remove_outliers(df)
self.cleaned_rows = len(df)
self._generate_report()
return dfThe pipeline follows a scientific strategy:
- Initialize monitoring variables to observe cleansing progress
- Arrange logging to seize pipeline execution particulars
- Execute cleansing phases in a logical sequence
- Generate experiences summarizing the cleansing outcomes
Writing the Knowledge Cleansing Logic
Let’s implement every cleansing stage with sturdy error dealing with:
Lacking Worth Dealing with
The next code will drop rows with lacking required fields and fill lacking elective fields utilizing median (for numerics) or ‘Unknown’ (for non-numerics).
def _handle_missing_values(self, df: pd.DataFrame) -> pd.DataFrame:
"""Deal with lacking values primarily based on subject necessities"""
for column, guidelines in self.schema.objects():
if column in df.columns:
if guidelines.get('required', False):
# Take away rows with lacking required fields
missing_count = df[column].isnull().sum()
if missing_count > 0:
self.errors.append(f"Eliminated {missing_count} rows with lacking {column}")
df = df.dropna(subset=[column])
else:
# Fill elective lacking values
if df[column].dtype in ['int64', 'float64']:
df[column].fillna(df[column].median(), inplace=True)
else:
df[column].fillna('Unknown', inplace=True)
return dfKnowledge Kind Validation
The next code converts columns to specified sorts and removes rows the place conversion fails.
def _validate_data_types(self, df: pd.DataFrame) -> pd.DataFrame:
"""Convert and validate knowledge sorts"""
for column, guidelines in self.schema.objects():
if column in df.columns:
expected_type = guidelines['type']
attempt:
if expected_type == 'datetime':
df[column] = pd.to_datetime(df[column], errors="coerce")
elif expected_type == int:
df[column] = pd.to_numeric(df[column], errors="coerce").astype('Int64')
elif expected_type == float:
df[column] = pd.to_numeric(df[column], errors="coerce")
# Take away rows with conversion failures
invalid_count = df[column].isnull().sum()
if invalid_count > 0:
self.errors.append(f"Eliminated {invalid_count} rows with invalid {column}")
df = df.dropna(subset=[column])
besides Exception as e:
self.logger.error(f"Kind conversion error for {column}: {e}")
return dfIncluding Validation with error monitoring
Our constraint validation system assures that the info is inside limits and the format is suitable:
def _apply_constraints(self, df: pd.DataFrame) -> pd.DataFrame:
"""Apply field-specific constraints"""
for column, guidelines in self.schema.objects():
if column in df.columns:
initial_count = len(df)
# Vary validation
if 'min_value' in guidelines:
df = df[df[column] >= guidelines['min_value']]
if 'max_value' in guidelines:
df = df[df[column] <= guidelines['max_value']]
# Sample validation for strings
if 'sample' in guidelines and df[column].dtype == 'object':
import re
sample = re.compile(guidelines['pattern'])
df = df[df[column].astype(str).str.match(sample, na=False)]
removed_count = initial_count - len(df)
if removed_count > 0:
self.errors.append(f"Eliminated {removed_count} rows failing {column} constraints")
return dfConstraint-Primarily based & Cross-Area Validation
Superior validation is normally wanted when relations between a number of fields are thought-about:
def _cross_field_validation(self, df: pd.DataFrame) -> pd.DataFrame:
"""Validate relationships between fields"""
initial_count = len(df)
# Instance: Signup date shouldn't be sooner or later
if 'signup_date' in df.columns:
future_signups = df['signup_date'] > datetime.now()
df = df[~future_signups]
eliminated = future_signups.sum()
if eliminated > 0:
self.errors.append(f"Eliminated {eliminated} rows with future signup dates")
# Instance: Age consistency with signup date
if 'age' in df.columns and 'signup_date' in df.columns:
# Take away data the place age appears inconsistent with signup timing
suspicious_age = (df['age'] < 13) & (df['signup_date'] < datetime(2010, 1, 1))
df = df[~suspicious_age]
eliminated = suspicious_age.sum()
if eliminated > 0:
self.errors.append(f"Eliminated {eliminated} rows with suspicious age/date mixtures")
return dfOutlier Detection and Removing
The consequences of outliers will be excessive on the outcomes of the evaluation. The pipeline has a sophisticated methodology for detecting such outliers:
def _remove_outliers(self, df: pd.DataFrame) -> pd.DataFrame:
"""Take away statistical outliers utilizing IQR methodology"""
numeric_columns = df.select_dtypes(embrace=[np.number]).columns
for column in numeric_columns:
if column in self.schema:
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = (df[column] < lower_bound) | (df[column] > upper_bound)
outlier_count = outliers.sum()
if outlier_count > 0:
df = df[~outliers]
self.errors.append(f"Eliminated {outlier_count} outliers from {column}")
return dfOrchestrating the Pipeline
Right here’s our full, compact pipeline implementation:
class DataCleaningPipeline:
def __init__(self, schema: Dict[str, Any]):
self.schema = schema
self.errors = []
self.cleaned_rows = 0
self.total_rows = 0
logging.basicConfig(degree=logging.INFO)
self.logger = logging.getLogger(__name__)
def clean_and_validate(self, df: pd.DataFrame) -> pd.DataFrame:
self.total_rows = len(df)
self.logger.information(f"Beginning pipeline with {self.total_rows} rows")
# Execute cleansing phases
df = self._handle_missing_values(df)
df = self._validate_data_types(df)
df = self._apply_constraints(df)
df = self._remove_outliers(df)
self.cleaned_rows = len(df)
self._generate_report()
return df
def _generate_report(self):
"""Generate cleansing abstract report"""
self.logger.information(f"Pipeline accomplished: {self.cleaned_rows}/{self.total_rows} rows retained")
for error in self.errors:
self.logger.warning(error)Instance Utilization
Let’s see an illustration of a pipeline in motion with an actual dataset:
# Create pattern problematic knowledge
sample_data = pd.DataFrame({
'user_id': [1, 2, None, 4, 5, 999999],
'e-mail': ['[email protected]', 'invalid-email', '[email protected]', None, '[email protected]', '[email protected]'],
'age': [25, 150, 30, -5, 35, 28], # Accommodates invalid ages
'signup_date': ['2023-01-15', '2030-12-31', '2022-06-10', '2023-03-20', 'invalid-date', '2023-05-15'],
'rating': [85.5, 105.0, 92.3, 78.1, -10.0, 88.7] # Accommodates out-of-range scores
})
# Initialize and run pipeline
pipeline = DataCleaningPipeline(VALIDATION_SCHEMA)
cleaned_data = pipeline.clean_and_validate(sample_data)
print("Cleaned Knowledge:")
print(cleaned_data)
print(f"nCleaning Abstract: {pipeline.cleaned_rows}/{pipeline.total_rows} rows retained")Output:
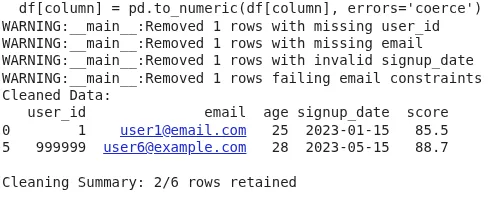
The output reveals the ultimate cleaned DataFrame after dropping rows with lacking required fields, invalid knowledge sorts, constraint violations (like out-of-range values or dangerous emails), and outliers. The abstract line experiences what number of rows have been retained out of the entire. This ensures solely legitimate, analysis-ready knowledge strikes ahead, enhancing high quality, lowering errors, and making your pipeline dependable and reproducible.
Extending the Pipeline
Our pipeline has been made extensible. Under are some concepts for enhancement:
- Customized Validation Guidelines: Incorporate domain-specific validation logic by extending the schema format to just accept customized validation capabilities.
- Parallel Processing: Course of massive datasets in parallel throughout a number of CPU cores utilizing applicable libraries resembling multiprocessing.
- Machine Studying Integration: Herald anomaly detection fashions for detecting knowledge high quality points too intricate for rule-based methods.
- Actual-time Processing: Modify the pipeline for streaming knowledge with Apache Kafka or Apache Spark Streaming.
- Knowledge High quality Metrics: Design a broad high quality rating that components a number of dimensions resembling completeness, accuracy, consistency, and timeliness.

Conclusion
The notion of this kind of cleansing and validation is to test the info for all the weather that may be errors: lacking values, invalid knowledge sorts or constraints, outliers, and, in fact, report all this info with as a lot element as doable. This pipeline then turns into your place to begin for data-quality assurance in any type of knowledge evaluation or machine-learning job. A number of the advantages you get from this strategy embrace automated QA checks so no errors go unnoticed, reproducible outcomes, thorough error monitoring, and easy set up of a number of checks with specific area constraints.
By deploying pipelines of this kind in your knowledge workflows, your data-driven selections will stand a far larger likelihood of being appropriate and exact. Knowledge cleansing is an iterative course of, and this pipeline will be prolonged in your area with further validation guidelines and cleansing logic as new knowledge high quality points come up. Such a modular design permits new options to be built-in with out clashes with presently applied ones.
Continuously Requested Questions
A. It’s an automatic workflow that detects and fixes lacking values, kind mismatches, constraint violations, and outliers to make sure solely clear knowledge reaches evaluation or modeling.
A. Pipelines are quicker, constant, reproducible, and fewer error-prone than guide strategies, particularly vital when working with massive datasets.
A. Rows with lacking required fields or failed validations are dropped. Elective fields get default values like medians or “Unknown”.
Gen AI Intern at Analytics Vidhya
Division of Laptop Science, Vellore Institute of Know-how, Vellore, India
I’m presently working as a Gen AI Intern at Analytics Vidhya, the place I contribute to progressive AI-driven options that empower companies to leverage knowledge successfully. As a final-year Laptop Science pupil at Vellore Institute of Know-how, I convey a stable basis in software program improvement, knowledge analytics, and machine studying to my position.
Be happy to attach with me at [email protected]
Login to proceed studying and luxuriate in expert-curated content material.