

{kind=link}
NOTE: As of July 15, the Amazon S3 Vectors Integration with Amazon OpenSearch Service is in preview launch and is topic to vary.
The way in which we retailer and search via knowledge is evolving quickly with the development of vector embeddings and similarity search capabilities. Vector search has turn out to be important for contemporary functions resembling generative AI and agentic AI, however managing vector knowledge at scale presents important challenges. Organizations usually wrestle with the trade-offs between latency, price, and accuracy when storing and looking via thousands and thousands or billions of vector embeddings. Conventional options both require substantial infrastructure administration or include prohibitive prices as knowledge volumes develop.
We now have a public preview of two integrations between Amazon Easy Storage Service (Amazon S3) Vectors and Amazon OpenSearch Service that provide you with extra flexibility in the way you retailer and search vector embeddings:
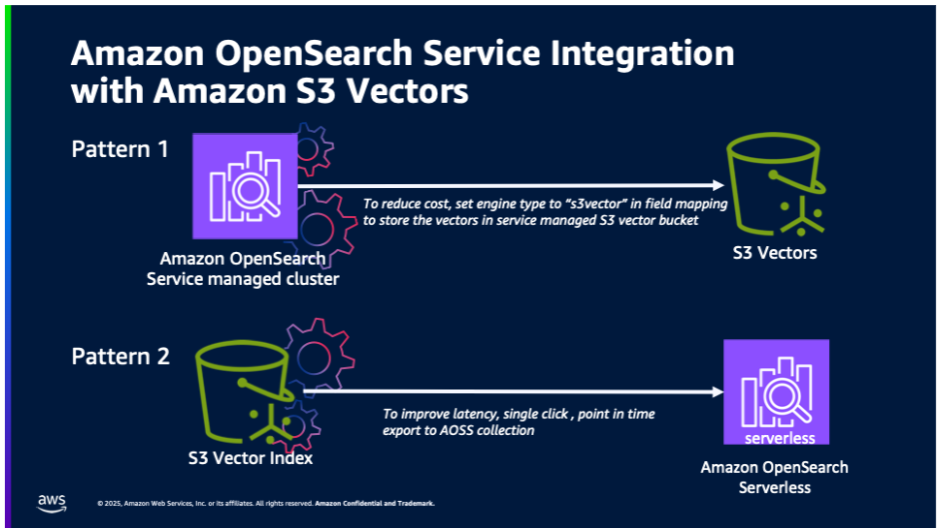
- Value-optimized vector storage: OpenSearch Service managed clusters utilizing service-managed S3 Vectors for cost-optimized vector storage. This integration will help OpenSearch workloads which can be keen to commerce off increased latency for ultra-low price and nonetheless wish to use superior OpenSearch capabilities (resembling hybrid search, superior filtering, geo filtering, and so forth).
- One-click export from S3 Vectors: One-click export from an S3 vector index to OpenSearch Serverless collections for high-performance vector search. Prospects who construct natively on S3 Vectors will profit from with the ability to use OpenSearch for sooner question efficiency.
Through the use of these integrations, you’ll be able to optimize price, latency, and accuracy by intelligently distributing your vector workloads by retaining rare queried vectors in S3 Vectors and utilizing OpenSearch in your most time-sensitive operations that require superior search capabilities resembling hybrid search and aggregations. Additional, OpenSearch efficiency tuning capabilities (that’s, quantization, k-nearest neighbor (knn) algorithms, and method-specific parameters) assist to enhance the efficiency with little compromise of price or accuracy.
On this publish, we stroll via this seamless integration, offering you with versatile choices for vector search implementation. You’ll learn to use the brand new S3 Vectors engine kind in OpenSearch Service managed clusters for cost-optimized vector storage and the way to use one-click export from S3 Vectors to OpenSearch Serverless collections for high-performance eventualities requiring sustained queries with latency as little as 10ms. By the tip of this publish, you’ll perceive how to decide on and implement the best integration sample primarily based in your particular necessities for efficiency, price, and scale.
Service overview
Amazon S3 Vectors is the primary cloud object retailer with native help to retailer and question vectors with sub-second search capabilities, requiring no infrastructure administration. It combines the simplicity, sturdiness, availability, and cost-effectiveness of Amazon S3 with native vector search performance, so you’ll be able to retailer and question vector embeddings straight in S3. Amazon OpenSearch Service offers two complementary deployment choices for vector workloads: Managed Clusters and Serverless Collections. Each harness Amazon OpenSearch’s highly effective vector search and retrieval capabilities, although every excels in several eventualities. For OpenSearch customers, the combination between S3 Vectors and Amazon OpenSearch Service provides unprecedented flexibility in optimizing your vector search structure. Whether or not you want ultra-fast question efficiency for real-time functions or cost-effective storage for large-scale vector datasets, this integration allows you to select the method that most closely fits your particular use case.
Understanding Vector Storage Choices
OpenSearch Service offers a number of choices for storing and looking vector embeddings, every optimized for various use instances. The Lucene engine, which is OpenSearch’s native search library, implements the Hierarchical Navigable Small World (HNSW) methodology, providing environment friendly filtering capabilities and robust integration with OpenSearch’s core performance. For workloads requiring extra optimization choices, the Faiss engine (Fb AI Similarity Search) offers implementations of each HNSW and IVF (Inverted File Index) strategies, together with vector compression capabilities. HNSW creates a hierarchical graph construction of connections between vectors, enabling environment friendly navigation throughout search, whereas IVF organizes vectors into clusters and searches solely related subsets throughout question time. With the introduction of the S3 engine kind, you now have a cheap choice that makes use of Amazon S3’s sturdiness and scalability whereas sustaining sub-second question efficiency. With this number of choices, you’ll be able to select probably the most appropriate method primarily based in your particular necessities for efficiency, price, and accuracy. As an illustration, in case your software requires sub-50 ms question responses with environment friendly filtering, Faiss’s HNSW implementation is the only option. Alternatively, if that you must optimize storage prices whereas sustaining cheap efficiency, the brand new S3 engine kind can be extra acceptable.
Resolution overview
On this publish, we discover two main integration patterns:
OpenSearch Service managed clusters utilizing service-managed S3 Vectors for cost-optimized vector storage.
For purchasers already utilizing OpenSearch Service domains who wish to optimize prices whereas sustaining sub-second question efficiency, the brand new Amazon S3 engine kind provides a compelling answer. OpenSearch Service mechanically manages vector storage in Amazon S3, knowledge retrieval, and cache optimization, eliminating operational overhead.
One-click export from an S3 vector index to OpenSearch Serverless collections for high-performance vector search.
To be used instances requiring sooner question efficiency, you’ll be able to migrate your vector knowledge from an S3 vector index to an OpenSearch Serverless assortment. This method is good for functions that require real-time response instances and provides you the advantages that include Amazon OpenSearch Serverless, together with superior question capabilities and filters, automated scaling and excessive availability, and no administration. The export course of mechanically handles schema mapping, vector knowledge switch, index optimization, and connection configuration.
The next illustration exhibits the 2 integration patterns between Amazon OpenSearch Service and S3 Vectors.
Stipulations
Earlier than you start, be sure you have:
- An AWS account
- Entry to Amazon S3 and Amazon OpenSearch Service
- An OpenSearch Service area (for the primary integration sample)
- Vector knowledge saved in S3 Vectors (for the second integration sample)
Integration sample 1: OpenSearch Service managed cluster utilizing S3 Vectors
To implement this sample:
- Create an OpenSearch Service Area utilizing OR1 cases on OpenSearch model 2.19.
- Whereas creating the OpenSearch Service area, select the Allow S3 Vectors as an engine choice within the Superior options part.
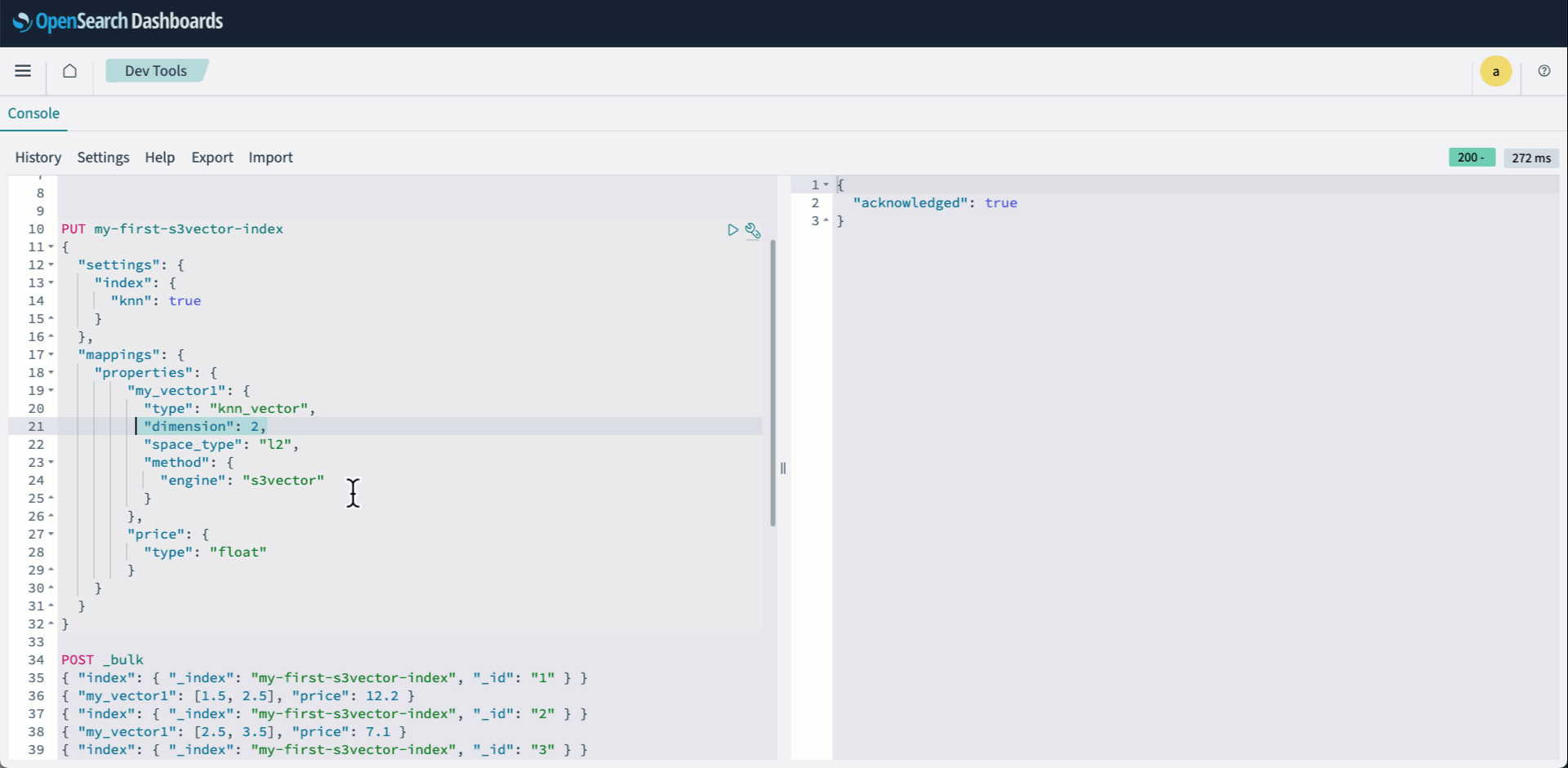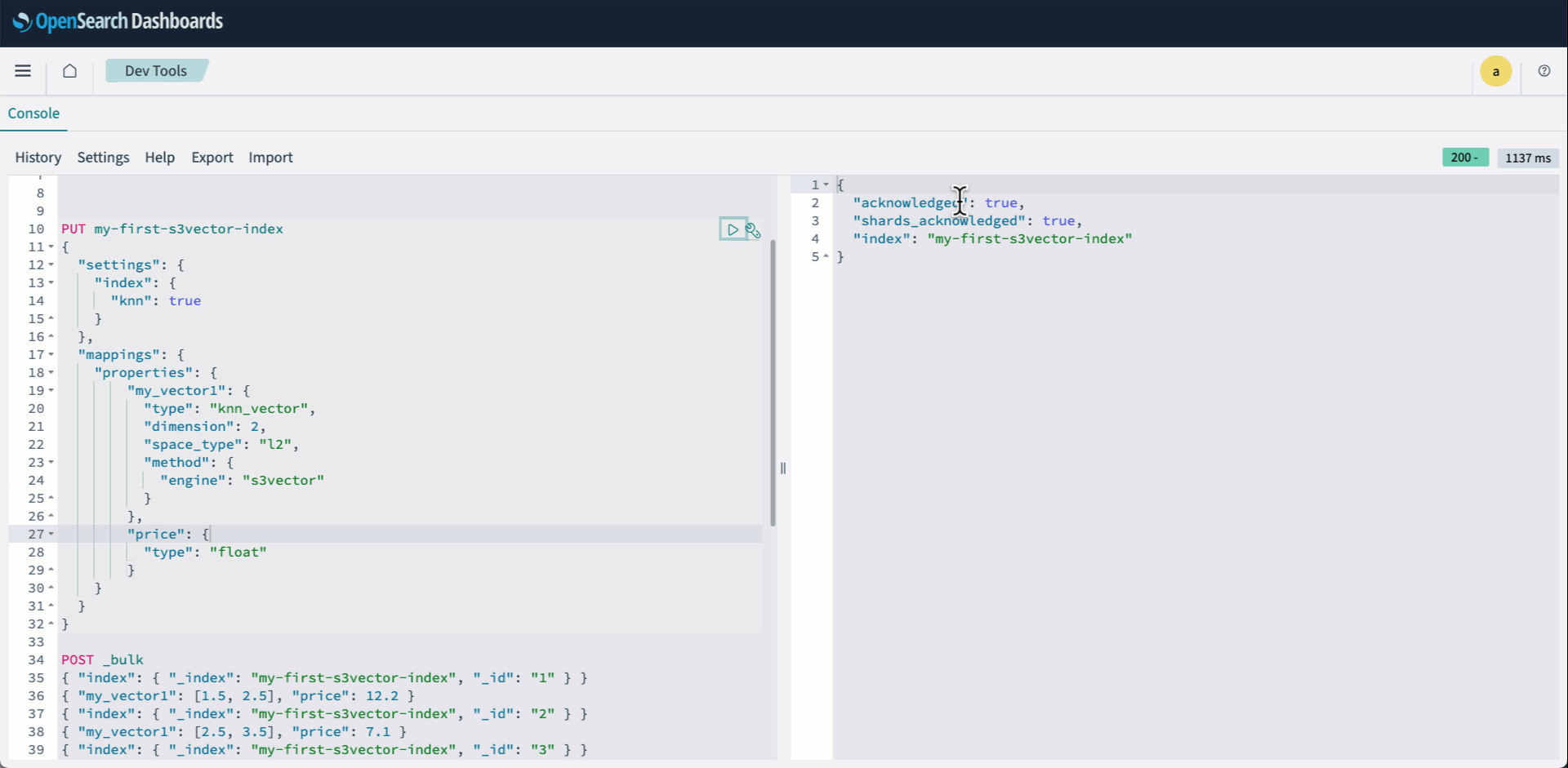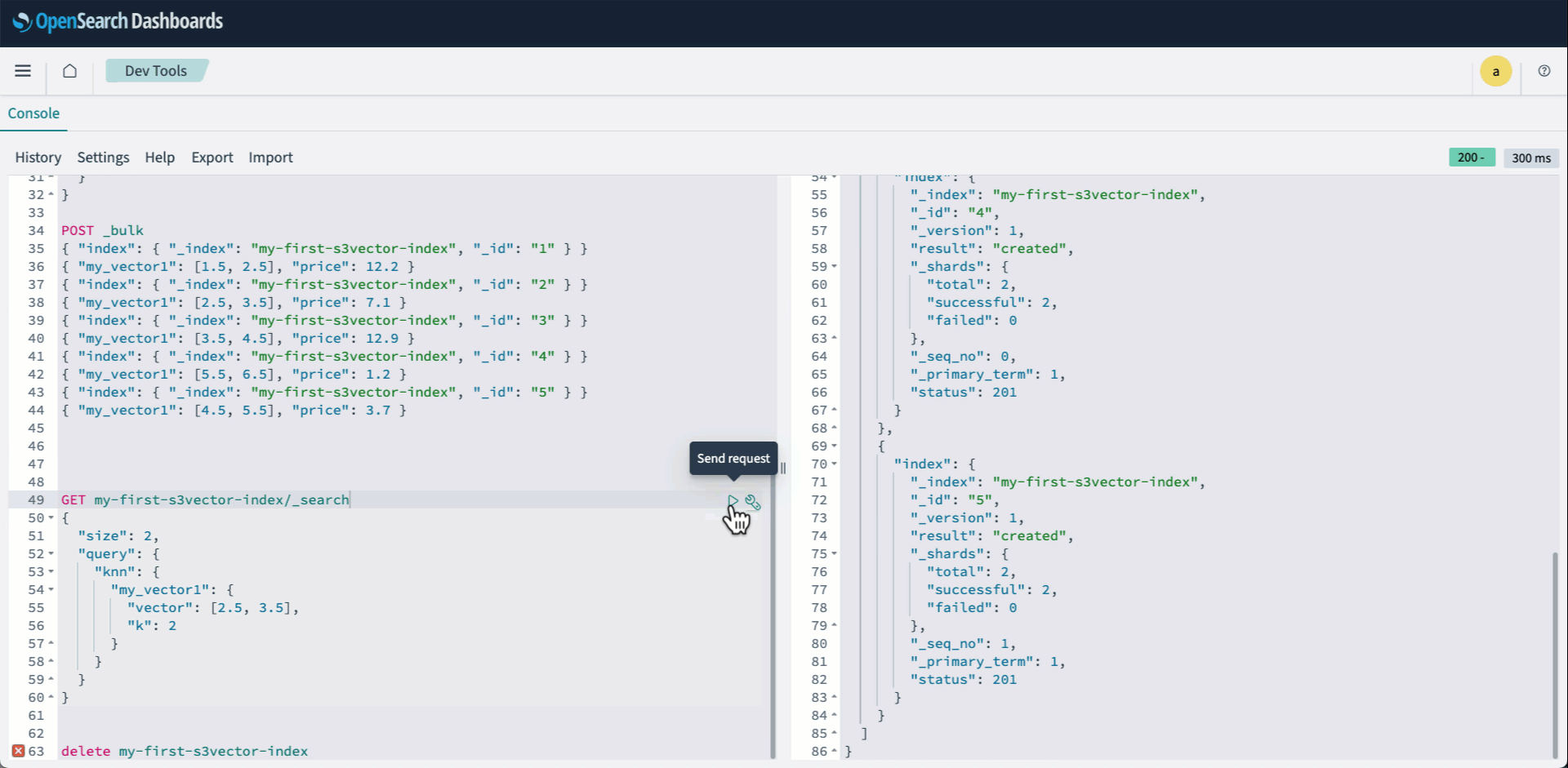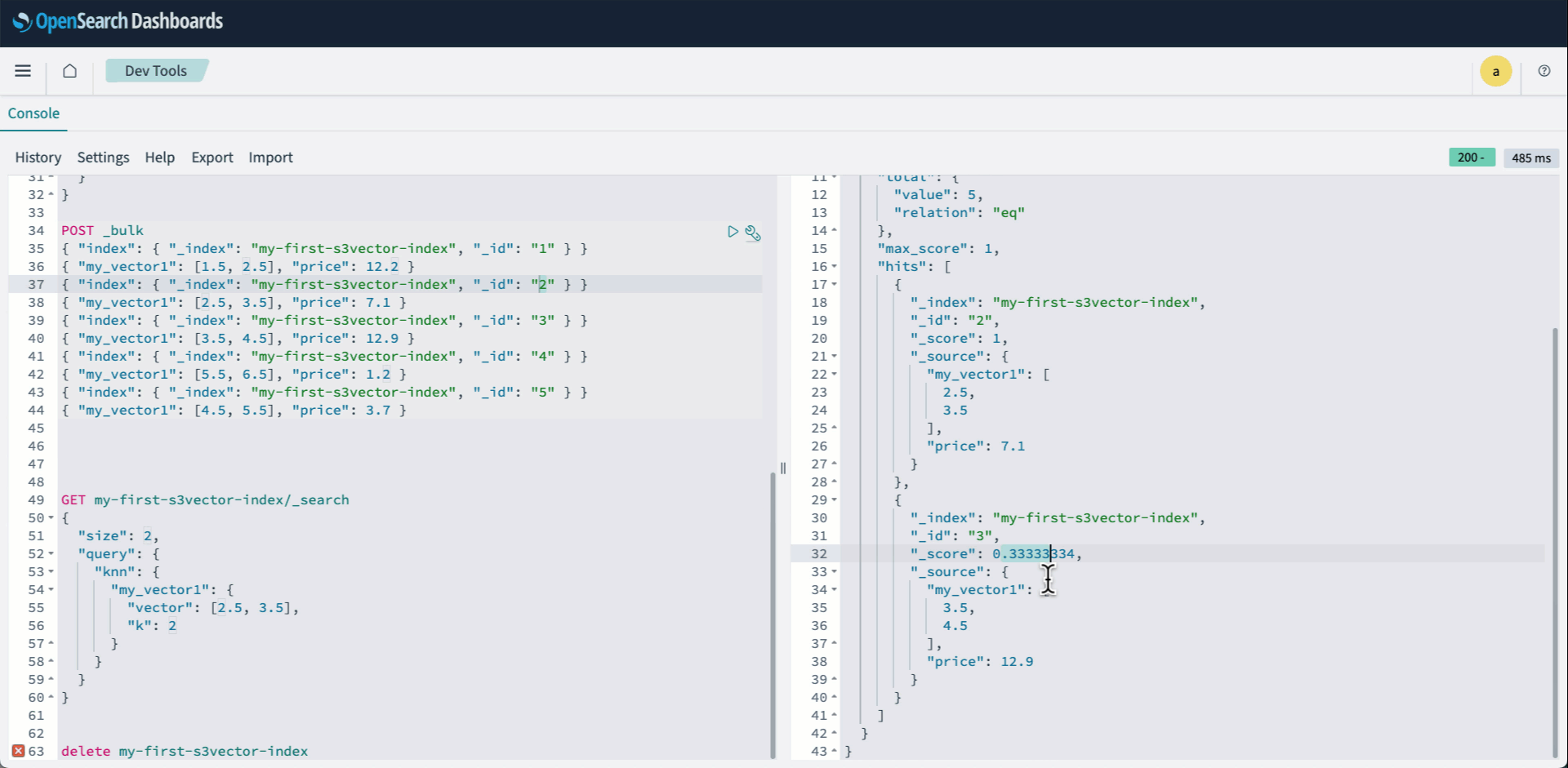
- Register to OpenSearch Dashboards and open Dev instruments. Then create your knn index and specify s3vector because the engine.
- Index your vectors utilizing the Bulk API:
- Run a knn question as standard:
The next animation demonstrates steps 2-4 above.
Integration sample 2: Export S3 vector indexes to OpenSearch Serverless
To implement this sample:
- Navigate to the AWS Administration Console for Amazon S3 and choose your S3 vector bucket.
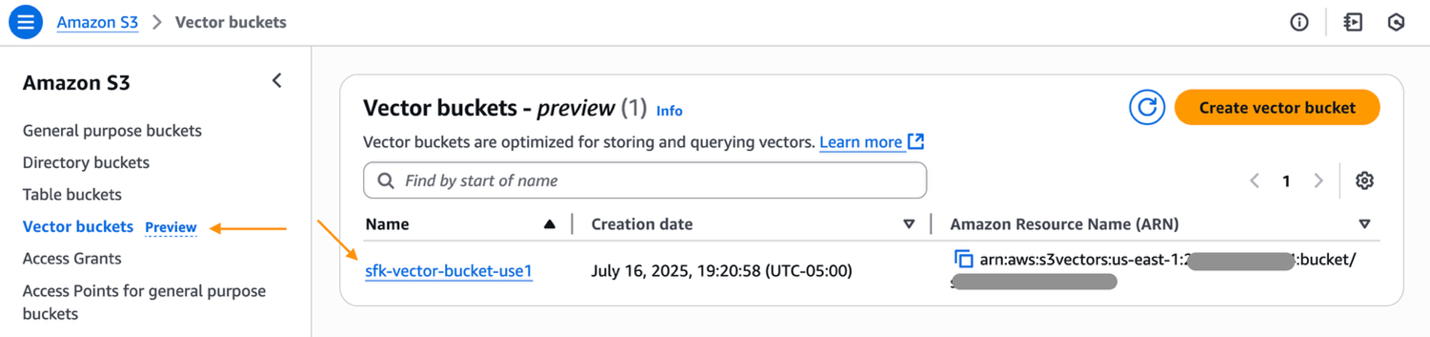
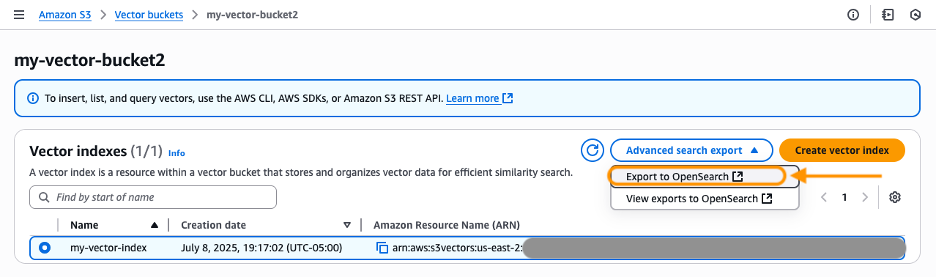
- Choose a vector index that you just wish to export. Underneath Superior search export, choose Export to OpenSearch.
Alternatively, you’ll be able to:
- Navigate to the OpenSearch Service console.
- Choose Integrations from the navigation pane.
- Right here you will notice a brand new Integration Template to Import S3 vectors to OpenSearch vector engine – preview. Choose Import S3 vector index.
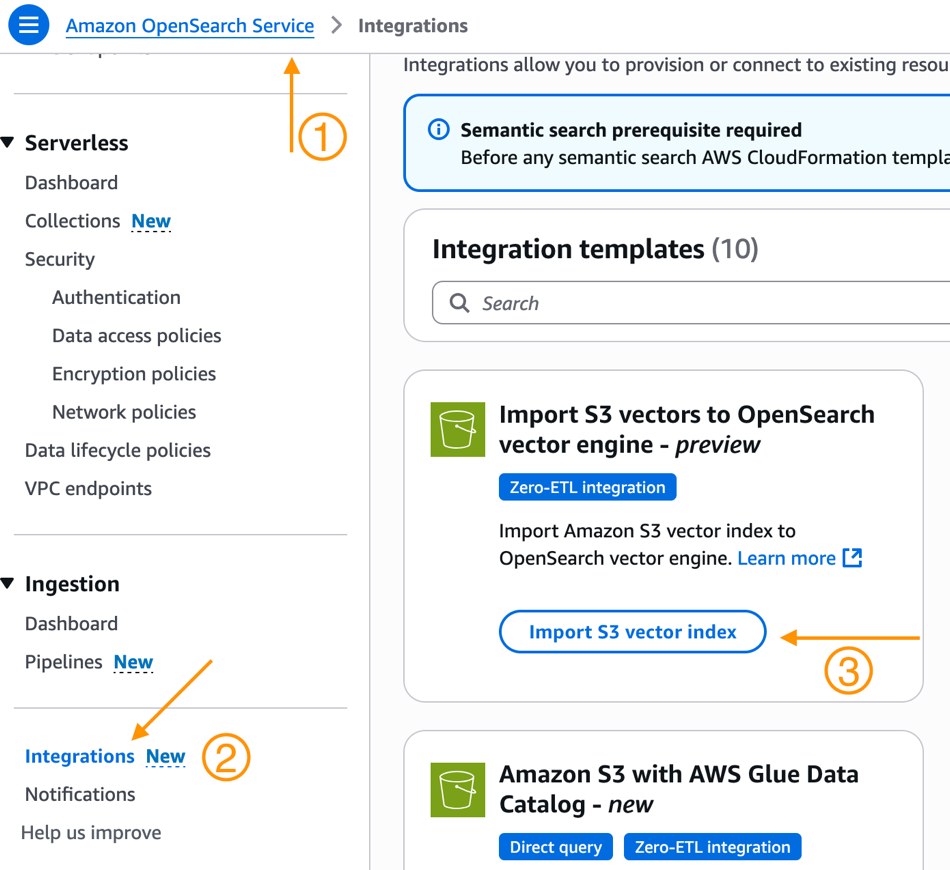
- You’ll now be dropped at the Amazon OpenSearch Service integration console with the Export S3 vector index to OpenSearch vector engine template pre-selected and pre-populated along with your S3 vector index Amazon Useful resource Title (ARN). Choose an current function that has the vital permissions or create a brand new service function.
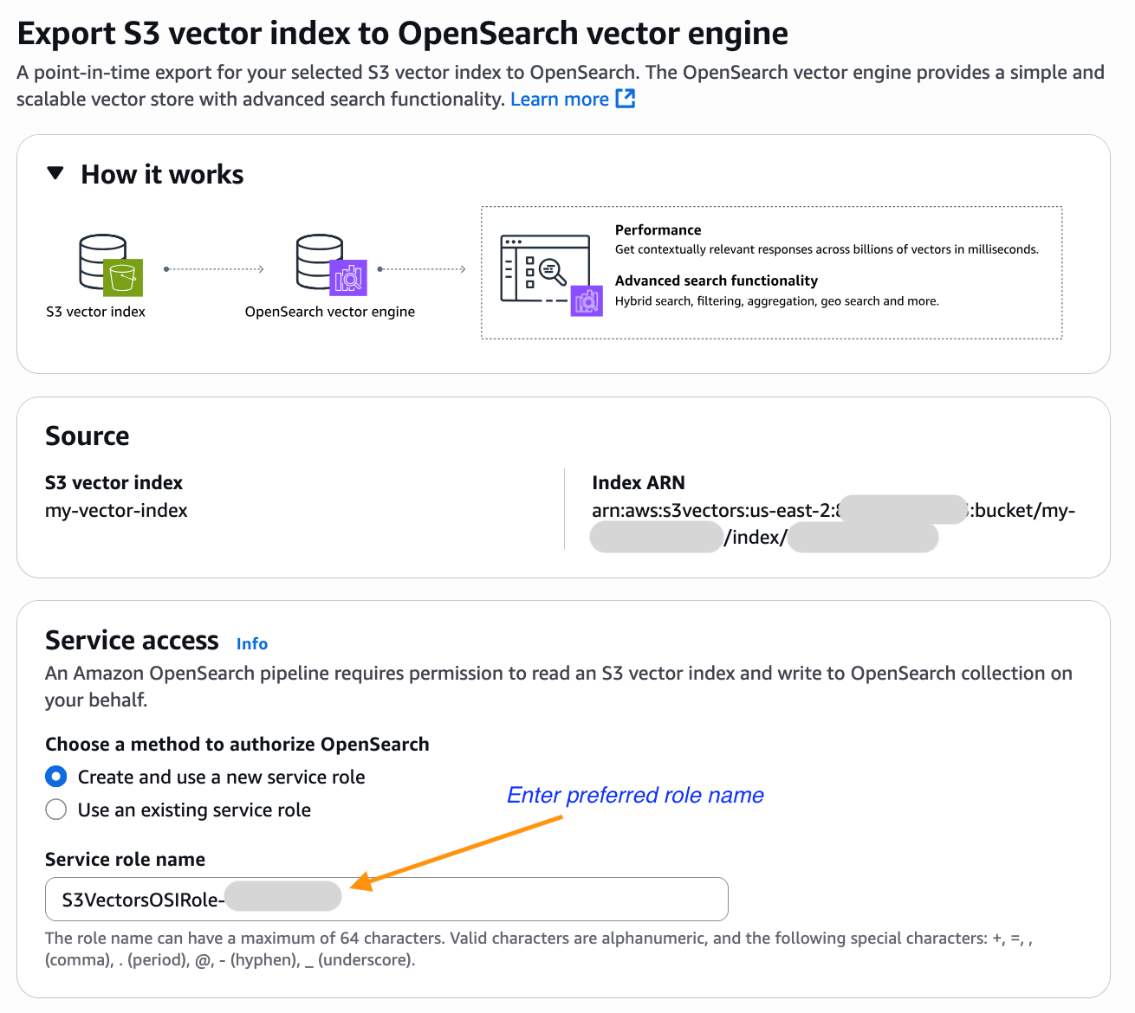
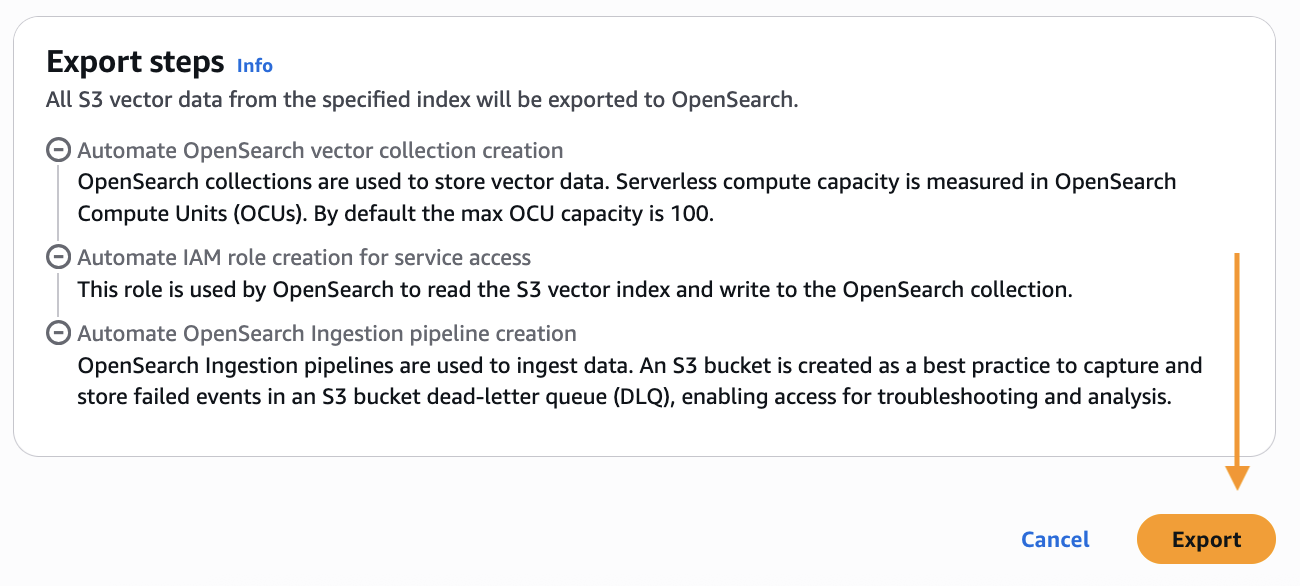
- Scroll down and select Export to begin the steps to create a brand new OpenSearch Serverless assortment and duplicate knowledge out of your S3 vector index into an OpenSearch knn index.
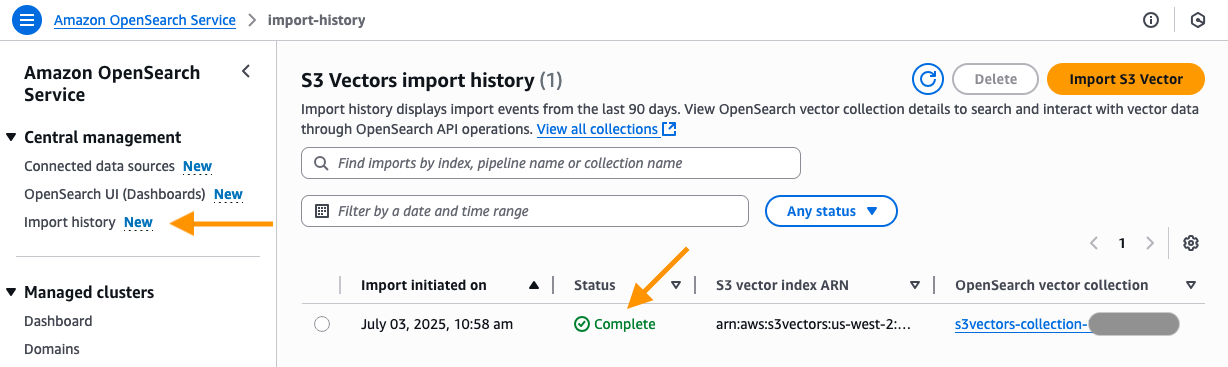
- You’ll now be taken to the Import historical past web page within the OpenSearch Service console. Right here you will notice the brand new job that was created emigrate your S3 vector index into the OpenSearch serverless knn index. After the standing modifications from In Progress to Full, you’ll be able to hook up with the brand new OpenSearch serverless assortment and question your new OpenSearch knn index.
The next animation demonstrates how to hook up with the brand new OpenSearch serverless assortment and question your new OpenSearch knn index utilizing Dev instruments.
Cleanup
To keep away from ongoing fees:
- For Sample 1:
- For Sample 2:
- Delete the import process from the Import historical past part of the OpenSearch Service console. Deleting this process will take away each the OpenSearch vector assortment and the OpenSearch Ingestion pipeline that was mechanically created by the import process.
Conclusion
The modern integration between Amazon S3 Vectors and Amazon OpenSearch Service marks a transformative milestone in vector search know-how, providing unprecedented flexibility and cost-effectiveness for enterprises. This highly effective mixture delivers the perfect of each worlds: The famend sturdiness and price effectivity of Amazon S3 merged seamlessly with the superior AI search capabilities of OpenSearch. Organizations can now confidently scale their vector search options to billions of vectors whereas sustaining management over their latency, price, and accuracy. Whether or not your precedence is ultra-fast question efficiency with latency as little as 10ms via OpenSearch Service, or cost-optimized storage with spectacular sub-second efficiency utilizing S3 Vectors or implementing superior search capabilities in OpenSearch, this integration offers the proper answer in your particular wants. We encourage you to get began immediately by attempting S3 Vectors engine in your OpenSearch managed clusters and testing the one-click export from S3 vector indexes to OpenSearch Serverless.
For extra data, go to:
In regards to the Authors
 Sohaib Katariwala is a Senior Specialist Options Architect at AWS centered on Amazon OpenSearch Service primarily based out of Chicago, IL. His pursuits are in all issues knowledge and analytics. Extra particularly he loves to assist prospects use AI of their knowledge technique to unravel modern-day challenges.
Sohaib Katariwala is a Senior Specialist Options Architect at AWS centered on Amazon OpenSearch Service primarily based out of Chicago, IL. His pursuits are in all issues knowledge and analytics. Extra particularly he loves to assist prospects use AI of their knowledge technique to unravel modern-day challenges.
 Mark Twomey is a Senior Options Architect at AWS centered on storage and knowledge administration. He enjoys working with prospects to place their knowledge in the best place, on the proper time, for the best price. Residing in Eire, Mark enjoys strolling within the countryside, watching films, and studying books.
Mark Twomey is a Senior Options Architect at AWS centered on storage and knowledge administration. He enjoys working with prospects to place their knowledge in the best place, on the proper time, for the best price. Residing in Eire, Mark enjoys strolling within the countryside, watching films, and studying books.
 Sorabh Hamirwasia is a senior software program engineer at AWS engaged on the OpenSearch Venture. His main curiosity embrace constructing price optimized and performant distributed methods.
Sorabh Hamirwasia is a senior software program engineer at AWS engaged on the OpenSearch Venture. His main curiosity embrace constructing price optimized and performant distributed methods.
 Pallavi Priyadarshini is a Senior Engineering Supervisor at Amazon OpenSearch Service main the event of high-performing and scalable applied sciences for search, safety, releases, and dashboards.
Pallavi Priyadarshini is a Senior Engineering Supervisor at Amazon OpenSearch Service main the event of high-performing and scalable applied sciences for search, safety, releases, and dashboards.
 Bobby Mohammed is a Principal Product Supervisor at AWS main the Search, GenAI, and Agentic AI product initiatives. Beforehand, he labored on merchandise throughout the total lifecycle of machine studying, together with knowledge, analytics, and ML options on SageMaker platform, deep studying coaching and inference merchandise at Intel.
Bobby Mohammed is a Principal Product Supervisor at AWS main the Search, GenAI, and Agentic AI product initiatives. Beforehand, he labored on merchandise throughout the total lifecycle of machine studying, together with knowledge, analytics, and ML options on SageMaker platform, deep studying coaching and inference merchandise at Intel.