

October 11, 2024
Within the ever-evolving world of expertise, Google has lengthy stood as a dominant power, shaping how we search, store, and devour data. However behind the scenes, the tech big has been partaking in practices that elevate important questions on its transparency, moral conduct, and affect. This text unveils how Google has manipulated its monopoly, significantly within the search engine optimisation trade, and the way it makes use of its merchandise to collect huge quantities of information — typically with out consumer consent. Now, the US Division of Justice has introduced that they could be breaking apart the completely different components of Google, together with breaking Chrome and the Google Play Retailer away from Google Search.
A lot of the testimony within the DOJ trial has been behind closed doorways, however this consequence actually begs the query, ‘what are we not being instructed about what Google has been doing?’ That is the primary article in a 3-part collection that’s designed to discover a brand new idea of how Google could also be getting a few of their crawling and rating information, and what the implications could be. This primary article will give high-level assumptions in regards to the concept, the second article will delve into the particulars of the speculation, and the third article will talk about the potential implications and subsequent steps.
Final week I revealed a video that outlined a brand new understanding of Google’s Cellular-First Indexing course of -which simply really accomplished after 6+ years; my finest estimate of how Google’s Crawling, Rendering and Indexing methods work. Along with describing how this new mannequin for understanding labored, I introduced various circumstantial proof and handy coincidences that led me to my conclusion. What’s most stunning to me, is that a lot of the proof was ‘hiding in plain sight’ within the type of Google worker quotes, official statements, bulletins, documentation and of their varied product Phrases and Circumstances.
Section II of Google’s Cellular-First Indexing is simply Chrome

I’ll level out right here that the visible theme of the presentation was UFO’s, and this was fairly intentional. I used this theme to preempt the detractors who I knew would name this new mannequin of understanding a loopy conspiracy concept. I’m fairly used to this sort of suggestions, as a result of it has been a mainstay of my profession, which has been marked by quite a lot of concepts and theories that have been initially deemed to be loopy, unattainable or at the least ‘of no consequence,’ however which have all been confirmed out over time.
I used to be the primary within the search engine optimisation area to give attention to cell search engine optimisation, when leaders within the trade mentioned that it didn’t exist and would by no means be essential. Earlier than it even had a reputation, I used to be speaking about utilizing model sheets to format one web page to work on each cell and desktop – an idea now often known as responsive design. I used to be additionally early in speaking in regards to the significance of optimizing cell apps for search as a bigger search engine optimisation model technique; I used to be very early in speaking in regards to the significance of entities for search engine optimisation and the primary to identify what I referred to as ‘Fraggles’ however what Google later introduced as ‘Passages.’ In all of those instances, my concepts have been referred to as into query or typically even ridiculed – typically by the identical people who find themselves nonetheless my detractors at present. Fortunately, they’ve been incorrect every time.
This text collection will add element to the ideas introduced within the video and talk about among the finer factors that might not be coated within the video. It can additionally tackle among the issues and pushback on the ideas introduced; whereas most individuals obtained the concepts with enthusiastic curiosity, some have been involved that there was not sufficient proof to help the brand new idea. As a lot as potential, these issues might be addressed right here.
It should be famous although, that at the least for the needs of this dialogue, we gained’t have the ability to take Google at their phrase – particularly within the justification or clarification of their information assortment behaviors. In recent times, Google has confirmed themselves to be disingenuous of their communication – even on the highest ranges, in court docket with the US Division of Justice; so we will’t count on that their communication to the remainder of the world has been any extra correct or trustworthy. Google typically justifies a lot of what they do with ideas like ‘web page efficiency’, ‘load time’, ‘consumer expertise’ and ‘search high quality’; however I contend that these targets are doubtless solely a part of the explanations Google makes a lot of their selections; Information that they accumulate will be shared throughout all of their platforms, and have many makes use of – not simply those that Google brazenly specify.
The very last thing that I need to spotlight earlier than leaping into the main points, is the concept that the ‘proof of abuse’ by Google will not be even crucial on this dialogue; What’s extra essential is the ‘proof of potential for abuse,’ which is at the moment going considerably unchecked due to lack of expert oversight and regulation. Whereas the DOJ is evaluating some abuses, it typically appears to give attention to essentially the most superficial and easy abuses – avoiding the extra technical discussions. The unlucky fact is that Google/Alphabet and the businesses below it management a lot information, entry and data around the globe – that even the *potential* for the misleading practices that I describe right here needs to be sufficient to warrant concern, push-back and additional investigation.
Google has Confirmed Themselves Untrustworthy within the Most Consequential Audiences
Court docket testimonies and authorized investigations have additional uncovered Google’s enterprise and authorized ways, together with actively hiding and destroying proof in ongoing lawsuits. Decide Donato described Google’s misleading practices in court docket an egregious violation, and referred to as Google’s habits within the trial a “frontal assault on the truthful administration of justice,” underscoring the gravity of the difficulty.
This raises a basic query: Why ought to we belief what Google tells us? The DOJ’s findings reveal important patterns of deception, not simply in proof preservation but in addition in secretive courtroom testimonies, the place Google has constantly shaded the reality to cowl up its true practices. Why can we within the search engine optimisation neighborhood suppose that Google can be any extra forthcoming to digital entrepreneurs – who’ve traditionally tried and succeeded in manipulating their algorithms to profit the web sites of our alternative? And who’ve constantly made their job more durable with any data and understanding that we achieve.
The reality is, Google will not be an correct narrator, particularly when it’s speaking to digital entrepreneurs and the search engine optimisation neighborhood. For years, they’ve used us as an unpaid military, to unfold their desires and wishes for particular forms of web site formatting to our shoppers, with the implied guarantees of a rating reward. In actuality, we have been making code simpler to crawl, index and course of into subject fashions for Google’s AI methods. There could also be nothing incorrect with that, besides when the result’s a Google AI system that makes use of our higher formatted web site information to interchange hyperlinks to web sites with unlinked and uncited solutions which have solely been made potential by the well-formatted information that Google crawled and processed.
Whereas complaining about Google rankings has been frequent for years, plainly the complaints have by no means been so wide-spread or problematic as they’ve been beginning with the launch of the primary Useful Content material Replace, which eliminated a lot of small publishers from the Google Index solely. The abuse doesn’t finish there although – As a result of there are accounts of web sites that de-indexed within the Useful Content material Replace, however that have been nonetheless quoted, practically verbatim, in a Google AI Overview with none hyperlink or attribution. In different instances, websites are nonetheless rating, however their content material is virtually out-right copied and proven in an AIO with out attribution however out-ranking the unique content material. In different instances, websites that bought hit by the Useful Content material Replace will not present up in AI Overviews that particularly point out the model identify, and as an alternative, associated websites that point out them are proven. Actions like this go past abuse to outright theft, however small publishers have virtually no recourse. A small enterprise that has lately misplaced a fundamental income would have little probability going up in opposition to Google and their well-trained groups of attorneys in court docket, and Google is aware of this.
Analysis and court docket instances have proven that Google deliberately offers preferential rankings to their very own properties – particularly when they’re properly monetized like YouTube, or present deep consumer information, like Maps and now the partially Google-owned Reddit. It’s with this new understanding of Google’s ethical turpitude, that I started reevaluating the essential understanding that the majority SEOs have about the way in which Google crawls, renders, indexes and ranks internet content material. This time, I targeted on what could have been left unsaid, particularly when it will create privateness issues for customers or present a possible profit for Google’s promoting and/or AI fashions.
The Hidden Position of Clicks and Engagement in Google’s Algorithm
Proof that got here from the Division of Justice (DOJ) case in opposition to Google and different sources have make clear practices that many within the search engine optimisation trade have suspected however couldn’t show till now – that Google has been leveraging Chrome click on and engagement information as a core a part of a three-part mannequin of their algorithm. Chrome has the most important market share of any browser world broad, capturing about 65% of the market on cell and desktop. For years, Google has downplayed or outright denied the position of clicks and consumer engagement as rating components in its algorithm. Google refers to this as a “proxy of engagement,” but they’ve gone to nice lengths to obscure this data from each the general public and the search engine optimisation trade.
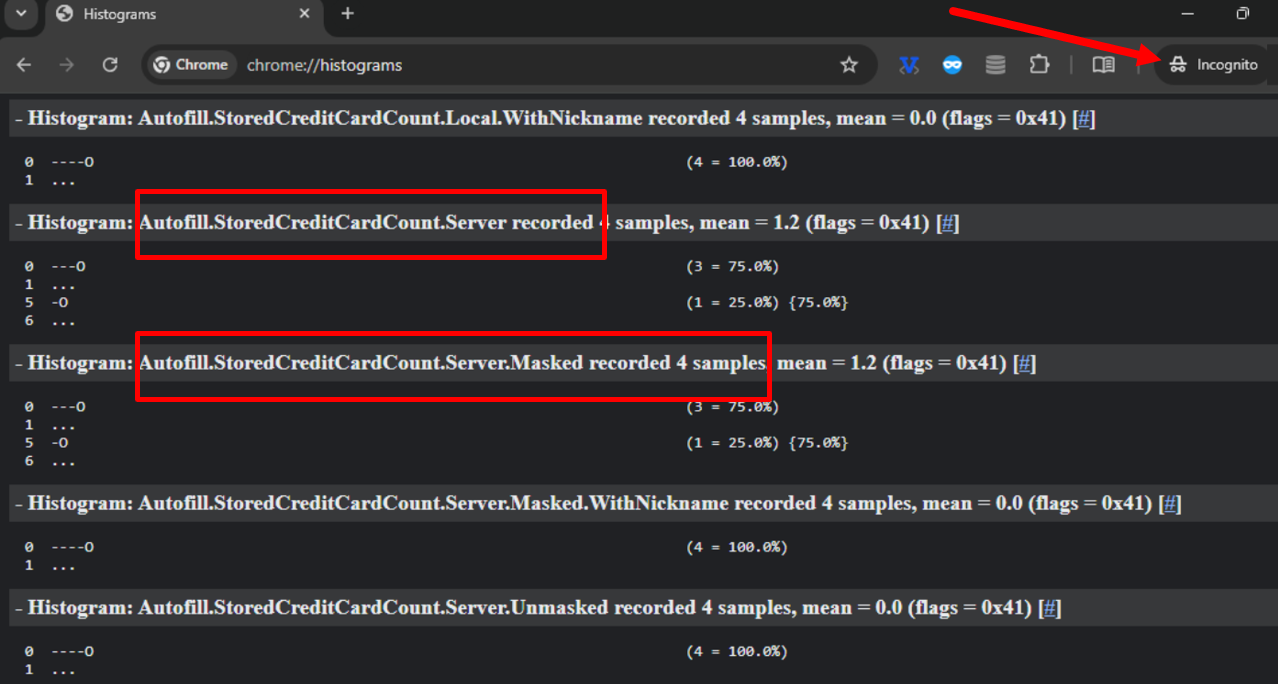
The current Google leak, uncovered by distinguished search engine optimisation consultants like Mike King, Dejan Petrovik and Rand Fishkin additional proved this out, highlighting particular click-based rating alterations like ‘NavBoost’. Apparently, a few of these alerts have been seen for years in Chrome’s Histogram monitoring. In Histograms (chrome://histograms), Chrome visibly tracks each click on, web page load, scroll depth, and even when auto-filled varieties and bank card fields are used — in each common and Incognito shopping modes. This information, gathered with out specific consent, from customers on each cell and desktop variations of Chrome with out specific consent, is presumably being fed again into Google’s algorithms to optimize search rankings, promoting fashions and different machine studying methods.
https://youtu.be/txNT1S28U3M?si=NV4ZHQP6oLM9LncN&t=206
Some have pushed again on the concept that Google is utilizing the histogram information for something aside from debugging, or that they might not use it in any respect, however this appears naive at finest. We will see data for Core Net Vitals, Google’s webpage loading and efficiency utility being actively tracked in histograms – even Credit score Card Auto fills in Incognito mode. It appears affordable if Google is monitoring a few of this information, they’re doubtless monitoring all of it; and even when it isn’t all used within the rating algorithm, it may very well be used for different issues like conversion monitoring for adverts and MUM Journey modeling, cohort modeling or UX habits & conversion modeling – doubtless related to what’s provided in Person Stream testing proven beneath..

Cellular-First Indexing: Extra Than Only a Crawling Change
The core of the video evaluations a brand new concept about how Google’s Cellular-First Indexing really works. The introduction of Cellular-First Indexing in 2016 marked a pivotal shift in how Google crawled and listed the net. They pre-announced the transition for a full yr; this shift went past the necessity to not block CSS and JavaScript information for bots, which was a part of the earlier ‘Cellular-Pleasant Replace’ from 2015; it pressured the significance of getting pages that have been well-formatted for cell browsers, ideally with using Responsive Design, which makes use of one URL with varied model sheets (CSS) to work properly on each cell and desktop screens. It started rolling out in earnest in 2018.
Traditionally, search engine optimisation’s had understood crawling, indexing and rating as three separate processes that Google utilized in its analysis of internet sites. With the launch of Cellular-First Indexing, they launched ‘rendering’ to the method. Rendering is the method of executing JavaScript and making use of CSS styling to really create the visible illustration of the web page.
The issue was, Google botched the launch, complicated and conflating crawling, rendering, and indexing processes at completely different factors within the launch; they referred to as it Cellular-First Indexing, which might make it seem to be the change was about how content material was listed – basically, the way it was organized and saved in Google’s database. However they described it as a change of the crawler from a desktop-based crawler to a mobile-based crawler, which made it seem to be it was about crawling; after which, after the launch, all Google talked about associated to Cellular-First Indexing was rendering, and the way their methods now wanted a second section of crawling to do the rendering.
With this main launch, Google additionally introduced that they might be switching from crawling with an older model of Chrome browser emulation (Chrome 41) within the bot, they might now crawl with what they referred to as the ‘Evergreen Bot’ which might keep updated with the model of Chrome that was stay -within a day or two. Whereas search engine optimisation’s will nonetheless militantly assert that crawling, indexing, rendering and rating are all completely different and distinct processes, it actually appeared to me like crawling, rendering and indexing had been mixed into one two-part course of the place they have been mixed to a point. Nonetheless, search engine optimisation’s believed that this new course of for Cellular-First Indexing was largely about switching to a cell crawler, and two-phase rendering.
What I observed, after the launch of Cellular-First Indexing was that Google was capable of make extra small algorithm updates in a shorter time frame, and that Google unexpectedly had a greater understanding of matters, or what we name ‘entities’ in search engine optimisation. This commentary was sturdy sufficient that I re-cast Cellular-First Indexing as Entity-First Indexing, since Google had really been utilizing a smartphone bot as their main crawler for years when Cellular-First Indexing launched, and for the reason that influence of the replace appeared much less about Cellular formatting, and extra about subject understanding. In a chat at MozCon 2018, I referred to as it ‘A Complete New Google.’
My suspicions grew even stronger when I discovered this quote from Ben Gomes, a long-time Google Search architect, and one of many fundamental individuals credited with constructing the Cellular-First Indexing system. In an interview with FastCompany’s Harry McCracken from 2018, [Ben] Gomes framed Google’s problem as “taking [the PageRank algorithm] from one machine to an entire bunch of machines, and so they
weren’t excellent machines on the time.” This appears to be speaking explicitly a couple of distributed system – which might be mentioned extra at size within the subsequent article on this collection.
Trying again now, it appears extra apparent that Google was solely protecting their Evergreen Bot up with Chrome releases and understanding matters/entities higher as a result of Google was utilizing our native installations of Chrome for the second section of crawling – AKA rendering, at the least to a point; and certain that they have been additionally utilizing our native compute energy to pre-process the web site information to arrange it into subject fashions for entity understanding – what Google calls The Subject Layer; And it’s this concept that adjustments our understanding of how Google actually works.
I hope this text has began to indicate you why Google would need – or certainly want – to make use of customers’ Google Chrome cases to assist their crawling efforts. I’ll keep it up within the subsequent installment to discover extra ideas round native JavaScript execution, and the make-up of the Chrome utility contents itself on Home windows gadgets. Within the last article on this collection, I’ll spotlight implications, as a result of on the very least, I believe Google has inquiries to reply.