

{kind=link}
Characteristic engineering is the inspiration of sturdy machine studying techniques, however the conventional course of is usually guide, time-consuming, and depending on area experience. Whereas efficient, it could possibly miss deeper alerts hidden in unstructured knowledge corresponding to textual content, logs, and consumer interactions.
Massive Language Fashions change this by serving to machines perceive language, extract that means, and generate richer options routinely. This shift opens new methods to construct smarter ML pipelines. This text affords a sensible information to function engineering utilizing LLMs.
What’s Characteristic Engineering with LLMs?
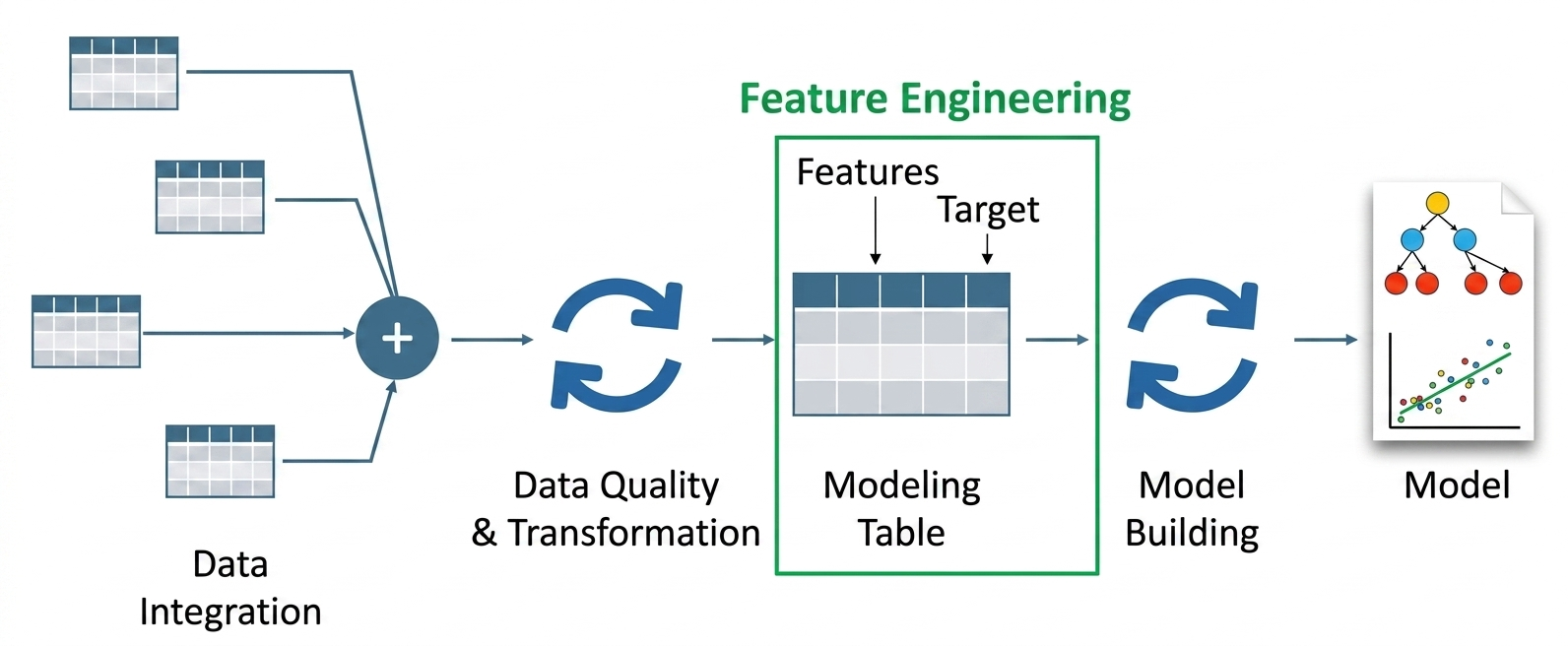
The method of function engineering with LLMs makes use of giant language fashions to develop and modify enter options that machine studying techniques require. Your system extracts semantic that means and structured alerts from uncooked knowledge by way of the appliance of LLMs as a substitute of utilizing solely guide transformations.
The brand new method to function engineering allows engineers to develop machine studying fashions by way of totally different strategies that embrace each numeric transformations and context-based representations.
Characteristic engineering with LLMs makes use of pretrained language fashions to rework uncooked inputs into structured high-dimensional representations which assist fashions obtain higher efficiency. The fashions use context to find out relationships between parts whereas creating options that specific that means past statistical patterns.
The way it Differs from Conventional Characteristic Engineering
Conventional function engineering creates guidelines and makes use of aggregation and transformation strategies to construct options. LLM-based function engineering extracts that means and consumer intentions and relationship knowledge which guide encoding fails to seize.
The Shift: From Handbook Options to Semantic Options
Machine studying develops fashions by way of its use of handmade options which embrace one-hot vectors and TF-IDF and standardized numerical values. Handbook options include restrictions as a result of they don’t take into account context and require specialised data and they don’t deal with delicate variations. The TF-IDF methodology handles phrases as separate entities which results in the lack of phrase relationships and emotional that means.
- Limitations of conventional strategies: Handbook function creation requires everlasting system connections and particular area experience. The system fails to incorporate each normal data and complex connections. A bag-of-words mannequin requires extra data than “chilly meals” to acknowledge damaging emotions. Human assets want to spend so much of time to determine all distinctive conditions.
- Position of LLMs in context: LLMs perform of their respective contexts by way of LLMs which make use of their coaching from intensive textual content databases to accumulate data and acknowledge patterns. The system understands language context by way of their presence of world data and skill to understand hidden messages. The system extracts semantic options from knowledge by way of LLMs which create computerized options that determine knowledge parts like sentiment and subject and threat classes.
- Why this shift issues: The significance of this transition comes from its means to indicate that semantic options ship higher outcomes than human-created options when coping with sophisticated duties. The system wants fewer function heuristics for its operations which leads to quicker testing processes.
Core Methods in Characteristic Engineering with LLMs
This part will illustrate the important thing strategies with code examples. We generate small pattern knowledge and present how options are derived.
Embeddings as Options
LLMs produce dense semantic vectors from textual content. The extracted embeddings perform as numeric options which allow the mannequin to grasp that means that exceeds fundamental phrase frequencies. We are able to use a transformer mannequin to create 384-dimensional sentence embeddings by way of sentence encoding.
from sentence_transformers import SentenceTransformer
mannequin = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["I love machine learning", "The movie was fantastic"]
embeddings = mannequin.encode(sentences)
print("Embeddings form:", embeddings.form)Output:
Embeddings form: (2, 384)
The output form (2, 384) exhibits two sentences mapped into 384-dimensional dense vectors (one per sentence). The vectors symbolize semantic properties of the textual content which embrace associated meanings and emotional expressions.
When to make use of embeddings vs conventional options:
from sklearn.feature_extraction.textual content import TfidfVectorizer
docs = [
"The cat sat on the mat",
"The dog ate the cat",
]
# Conventional TF-IDF: sparse bag-of-words
tfidf = TfidfVectorizer()
X_tfidf = tfidf.fit_transform(docs)
# LLM embeddings: dense semantic options
X_emb = mannequin.encode(docs)
print("TF-IDF function form:", X_tfidf.form)
print("LLM embedding function form:", X_emb.form)Output:
TF-IDF function form: (2, 6)LLM embedding function form: (2, 384)
The TF-IDF options create a (2×6) sparse matrix which accommodates six distinctive phrases, whereas the LLM embeddings exist as (2×384) dense vectors. The embeddings current that means of phrases of their context as a result of they present how synonyms relate to one another with the instance of “cat” and “canine”. Use semantic options from embeddings whereas conventional options work for easy numeric knowledge and high-frequency categorical knowledge that requires sparse encoding.
We are able to immediate the LLM to extract particular structured info from textual content. The mannequin outputs may be parsed into options.
from transformers import pipeline
evaluations = [
"The phone battery lasts all day and performance is smooth",
"The laptop overheats and is very slow",
]
extractor = pipeline("text2text-generation", mannequin="google/flan-t5-base")
immediate = """
Extract options: sentiment, product_issue, efficiency
Textual content: The laptop computer overheats and could be very sluggish
"""
end result = extractor(immediate, max_length=50)
print(end result[0]["generated_text"])Output:
sentiment: damaging, product_issue: overheating, efficiency: sluggish
We use the LLM immediate which states “Extract sentiment (optimistic/damaging), topic, and urgency (low/medium/excessive) from this assessment.” The mannequin returns structured options as a JSON-like dictionary. The options of sentiment, topic, and urgency now exist as separate columns which we will enter into our classifier system
A JSON schema may be enforced in an invocation in order that constant outputs are ensured. For instance:
immediate = """
Extract in JSON format:
{
"sentiment": "",
"challenge": "",
"efficiency": ""
}
Textual content: The cellphone battery lasts all day and efficiency is clean
"""
end result = extractor(immediate, max_length=100)
print(end result[0]["generated_text"])Output:
{
"sentiment": "optimistic",
"challenge": "none",
"efficiency": "clean"
}
Semantic Characteristic Era
LLMs generate recent descriptive attributes which may be utilized to each single rows and particular person knowledge values.
knowledge = [
{"review": "Great camera quality but battery drains fast"},
{"review": "Affordable and durable, good for daily use"},
]
immediate = """
Generate a brand new function known as 'user_intent' from this assessment:
Overview: Nice digicam high quality however battery drains quick
"""
end result = extractor(immediate, max_length=50)
print(end result[0]["generated_text"])Output:
user_intent: photography-focused however involved about battery
The LLM extracts consumer intent from the assessment by way of its evaluation of the textual content. The system transforms unprocessed textual content into structured options which present consumer desire for cameras and their concern about battery life. The system allows customers so as to add new columns which enhance mannequin understanding of consumer exercise patterns.
Context-Conscious Characteristic Creation
LLMs can generate textual content options once they use their data to research a function’s worth inside particular conditions. The LLM makes use of postal code info to elucidate the corresponding geographic space.
immediate = """
Infer buyer sort:
Overview: Inexpensive and sturdy, good for day by day use
"""
end result = extractor(immediate, max_length=50)
print(end result[0]['generated_text'])Output:
customer_type: budget-conscious sensible consumer
The LLM makes use of buyer assessment info to find out which buyer group the reviewer belongs to. The system transforms enter textual content right into a standardized label which shows the consumer’s two most important preferences of reasonably priced and sturdy merchandise. The system permits customers to implement a brand new function which allows fashions to categorize customers in accordance with their behavioural patterns and particular preferences.
Hybrid Characteristic Areas (Multi-Modal Pipelines)
Combining Tabular, Textual content, and Embeddings
We begin with numeric options and semantic options which we mix right into a hybrid vector.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"value": [1000, 500],
"ranking": [4.5, 3.0],
"assessment": [
"Excellent performance and battery life",
"Slow and heats up quickly",
],
})
embeddings = mannequin.encode(df["review"].tolist())
final_features = np.hstack([
df[["price", "rating"]].values,
embeddings,
])
print("Remaining function form:", final_features.form)Output:
Remaining function form: (2, 386)
The whole dataset now accommodates 2 rows which include 386 options. The unique tabular knowledge (value and ranking) is mixed with textual content embeddings from the evaluations. The system develops superior options by way of its mixture of structured knowledge and semantic textual content info which leads to higher mannequin efficiency.
Multi-Modal Characteristic Pipelines
We begin with numeric options and semantic options which we mix right into a hybrid vector.
def feature_pipeline(row):
embedding = mannequin.encode([row['review']])[0]
return listing(row[['price', 'rating']]) + listing(embedding)
options = df.apply(feature_pipeline, axis=1)
print(options.iloc[0][:5])Output:
[1000, 4.5, 0.023, -0.045, 0.067]
The whole dataset now accommodates 2 rows which include 386 options. The unique tabular knowledge (value and ranking) is mixed with textual content embeddings from the evaluations. The system develops superior options by way of its mixture of structured knowledge and semantic textual content info which leads to higher mannequin efficiency.
Finish-to-Finish Move (Information → LLM → Options → Mannequin)
On this part we’ll undergo the workflow demonstration which makes use of Transformers to extract options to be used with a fundamental classifier. For instance, take into account a sentiment classification process. For that in the first place we’ll take a pattern dataset.
import pandas as pd
df = pd.DataFrame({
"assessment": [
"Amazing product, delivery was super fast and packaging was perfect",
"Terrible quality, broke after one use and support was unhelpful",
"Good value for money, does what it promises",
"The product is okay, not great but not bad either",
"Excellent performance, exceeded my expectations completely",
"Very slow delivery and the product quality is disappointing",
"I love the design and build quality, highly recommended",
"Waste of money, stopped working within two days",
"Decent product for the price, but could be improved",
"Customer service was helpful but the product is average",
"Fantastic experience, will definitely buy again",
"The item arrived late and was damaged",
"Pretty good overall, satisfied with the purchase",
"Not worth the price, quality feels cheap",
"Absolutely शानदार product, very happy with it",
"Works fine but nothing exceptional",
"Horrible experience, I want a refund",
"The features are useful and performance is smooth",
"Mediocre quality, expected better at this price",
"Superb build quality and fast performance",
"Product is fine, delivery took too long",
"Loved it, exactly what I needed",
"It’s okay, does the job but has some issues",
"Worst purchase ever, completely useless",
"Very good quality and quick delivery",
"Average product, nothing special",
"Highly durable and reliable, great buy",
"Poor packaging and damaged item received",
"Satisfied with the purchase, decent performance",
"Not happy with the product, quality is subpar",
],
"label": [
1, 0, 1, 1, 1,
0, 1, 0, 1, 1,
1, 0, 1, 0, 1,
1, 0, 1, 0, 1,
0, 1, 1, 0, 1,
1, 1, 0, 1, 0,
],
})Now, we’ll transfer ahead to make an agentic pipeline that may assist in function engineering for a specific process. Like on this case it’ll carry out the sentiment evaluation.
from transformers import pipeline
from sentence_transformers import SentenceTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
# Step 1: Initialize fashions
llm = pipeline("text2text-generation", mannequin="google/flan-t5-base")
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Step 2: Characteristic Extraction Agent
def extract_features(textual content):
immediate = f"Extract sentiment (optimistic/damaging): {textual content}"
end result = llm(immediate, max_length=20)[0]["generated_text"]
return 1 if "optimistic" in end result.decrease() else 0
# Step 3: Construct Characteristic Set
df["sentiment_feature"] = df["review"].apply(extract_features)
embeddings = embedder.encode(df["review"].tolist())
X = np.hstack([
df[["sentiment_feature"]].values,
embeddings
])
y = df["label"]
# Step 4: Practice Mannequin
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2
)
mannequin = LogisticRegression()
mannequin.match(X_train, y_train)
# Step 5: Consider
accuracy = mannequin.rating(X_test, y_test)
print("Mannequin Accuracy:", accuracy)Output:
Mannequin Accuracy: 0.95
This exhibits the whole system operation which features from starting to finish. The LLM extracts a sentiment function from every assessment, which is mixed with embeddings to create richer inputs. The agentic function engineering strategy of this technique allows the mannequin to higher perceive textual content, which leads to elevated accuracy for sentiment prediction.
Actual-World Functions
The applying of LLMs in function engineering creates adjustments that impression varied industries. The answer exhibits means to carry out duties in several operational areas.
- Classification and NLP Techniques: LLMs ship superior textual parts which assist sentiment evaluation, chatbot growth, and doc classification duties in classification and NLP techniques.
- Tabular Machine Studying: LLMs allow all forms of duties to realize benefits from their capabilities. The LLM expertise converts unstructured knowledge from facet sources into usable options which a tabular mannequin can perceive.
- Area-Particular Use Circumstances: LLM options have discovered revolutionary functions in varied domains which embrace finance and healthcare and insurance coverage and extra industries. The LLM system in insurance coverage pricing allows actuaries to create computerized options which beforehand required human specialists. The LLM system makes use of automobile mannequin descriptions to find out threat scores which determine automobiles as “boy racer” fashions.
Limitations and Challenges
Characteristic engineering with LLMs offers advantages to customers, but it surely creates a number of obstacles which should be solved. The implementation course of requires all workforce members to grasp the present constraints. These embrace:
- Reliability and Reproducibility: The outputs of LLM techniques exhibit inconsistent habits as a result of mannequin adjustments and minor immediate alterations require new mannequin analysis. The system wants immediate logging and nil temperature settings to realize constant efficiency. Organizations face challenges in LLM deployment as a result of they need to deal with two facets which embrace API accessibility and model management.
- Bias and Interpretability: LLM techniques make their options obscure as a result of their dense embeddings perform as LLM core parts. The system would possibly create coaching data-based bias by way of its operational procedures. An LLM generates a function which connects the phrase “physician” to a specific gender in an implicit method. The auditing course of should study options to find out their equity.
- Over-Reliance on LLM Options: LLMs provide full automation which results in harmful outcomes by way of their facade of reliability. LLMs generate irrelevant options when customers present incorrect prompts. The LLM options ought to perform as supplementary instruments which customers ought to apply along with most important area options.
Conclusion
The sphere of machine studying growth experiences a significant transformation by way of the usage of function engineering with LLMs. The method now shifts its emphasis from guide knowledge transformation work towards creating automated options by way of semantic comprehension. This methodology allows researchers to develop new strategies for analyzing intricate and disorganized datasets.
The method requires exact implementation and thorough analysis and validation procedures to realize success. LLM capabilities mixed with human experience allow practitioners to develop AI techniques that function with better energy and scalability and effectiveness.
Regularly Requested Questions
A. It makes use of LLMs to show uncooked knowledge into semantic, structured options for machine studying fashions.
A. They convert textual content into dense vectors that seize that means, context, and relationships past easy phrase frequency.
A. LLM-based options may be inconsistent, biased, exhausting to interpret, and dangerous when used with out validation.
Good day! I am Vipin, a passionate knowledge science and machine studying fanatic with a robust basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am desperate to contribute my expertise in a collaborative surroundings whereas persevering with to study and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.