

{kind=link}
Amazon EMR Managed Scaling has been serving to clients routinely resize their clusters to optimize efficiency and scale back prices. We’re excited to introduce a major enhancement to this function: Superior Scaling for Amazon EMR. This new functionality offers extra flexibility to configure the specified useful resource utilization or efficiency ranges in your cluster utilizing a utilization-performance slider. After the slider is about, EMR Managed Scaling intelligently scales the cluster and optimizes cluster assets based mostly in your configured efficiency or useful resource utilization ranges.
Clients admire the simplicity of EMR Managed Scaling, the place they specify the minimal and most compute limits for his or her clusters and EMR Managed Scaling routinely resizes the cluster. EMR Managed Scaling constantly samples key metrics related to the workloads working on clusters and scales up or down accordingly. Nevertheless, clients’ workloads are more and more getting extra advanced, with variability throughout dimensions comparable to information volumes and value vs. SLA necessities. Consequently, clients desire to have extra levers to tune the scaling habits best suited for his or her workload. On this submit, we talk about the advantages of Superior Scaling for Amazon EMR and display the way it works by some instance eventualities.
Superior Scaling for Amazon EMR
Beforehand, clients who wished to regulate the default EMR Managed Scaling habits had no different choice however to disable EMR Managed Scaling and create customized automated scaling guidelines. Customized autoscaling guidelines created a number of issues:
- Customized autoscaling guidelines are usually not shuffle-aware and shuffle information is misplaced.
- Customized autoscaling just isn’t conscious of the appliance driver and might terminate it, failing all the job.
- Customized autoscaling may be slower to answer actual time wants.
These are a few of the the explanation why customized autoscaling just isn’t the suitable match. Clients wished out-of-the-box assist for Managed Scaling to deal with the scaling that optimizes for the purchasers finish objective to optimize value or efficiency. The brand new Superior Scaling functionality enhances the prevailing advantages of EMR Managed Scaling by introducing extra controls and serving to you configure the specified useful resource utilization or efficiency stage in your cluster utilizing a utilization-performance slider. EMR Superior Scaling then internally interprets intent into tailor-made algorithm technique (UtilizationPerformanceIndex), comparable to how rapidly to scale, how a lot to scale, and so forth, to make scaling choices for the cluster. This helps optimize cluster assets whereas ensuring we meet the efficiency or useful resource utilization intent set by the shopper.
For instance, for a cluster working a number of duties of comparatively brief period (order of seconds), EMR Managed Scaling beforehand used to scale up the cluster aggressively and conservatively scale it all the way down to keep away from detrimental affect to job runtimes. Though that is the suitable strategy for SLA-sensitive workloads, it won’t be optimum for patrons who’re nice with little delay however prefers saving value. Now, you’ll be able to configure EMR Managed Scaling habits appropriate in your workload sorts, and we’ll apply tailor-made optimization to intelligently add or take away nodes from the clusters. This helps you obtain the optimum price-performance in your clusters together with elevated flexibility of extra user-controls.
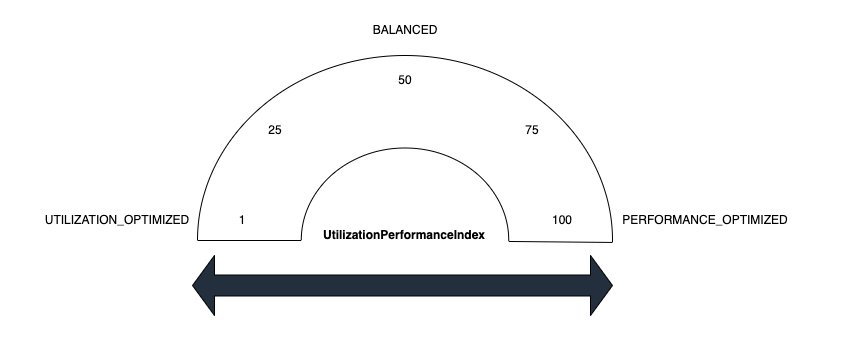
The worth you set for Superior Scaling optimizes your cluster to your necessities. Values vary from 1-100. Supported values are 1, 25, 50, 75 and 100. If you happen to set the index to values aside from these, it ends in a validation error. Scaling values map to resource-utilization methods. The next record defines a number of of those:
- Utilization optimized (1) – This setting prevents useful resource over provisioning. Use a low worth whenever you need to maintain prices low and to prioritize environment friendly useful resource utilization. It causes the cluster to scale up much less aggressively. This works properly for the use case when there are usually occurring workload spikes and also you don’t need assets to ramp up too rapidly.
- Balanced (50) – This balances useful resource utilization and job efficiency. This setting is appropriate for regular workloads the place most levels have a steady runtime. It’s additionally appropriate for workloads with a mixture of brief and long-running levels. We suggest beginning with this setting in the event you aren’t certain which to decide on.
- Efficiency optimized (100) – This technique prioritizes efficiency. The cluster scales up aggressively to make sure that jobs full rapidly and meet efficiency targets. Efficiency optimized is appropriate for service-level-agreement (SLA) delicate workloads the place quick run time is important.
Clients may also select intermediate values (25 and 75) for extra nuanced management. The intermediate values accessible present a center floor between methods to nice tune your cluster’s Superior Scaling habits.
Use instances and advantages
Amazon EMR’s Superior Scaling function improves cluster administration by providing dynamic adaptation to various enterprise necessities throughout industries. The function allows strategic timing of scaling insurance policies all through the day, with early morning hours devoted to workload preparation, peak enterprise hours specializing in most efficiency, night durations sustaining reasonable scaling for post-business processing, and in a single day hours optimized for cost-effective batch operations. This complete strategy permits organizations to fine-tune their useful resource allocation based mostly on particular operational patterns, in the end delivering an optimum stability between efficiency and cost-efficiency whereas making certain enterprise wants are met throughout totally different time zones and utilization patterns.
Scaling configuration
Within the following sections, we stroll by a variety of eventualities testing in opposition to a 3 TB TPC-DS dataset, then stroll you thru the outcomes of testing a pattern job. We wished to judge how Amazon EMR would reply with superior scaling insurance policies in eventualities optimizing cluster utilization, balancing efficiency with utilization, and aggressive efficiency necessities.
With Superior Scaling at present accessible by API and console assist coming quickly, we up to date present cluster configurations. We modified UtilizationPerformanceIndex with 1, 50, and 100, to correspond to the totally different scaling methods utilizing the put-managed-scaling-policy API with a sophisticated scaling technique, as seen within the following examples:
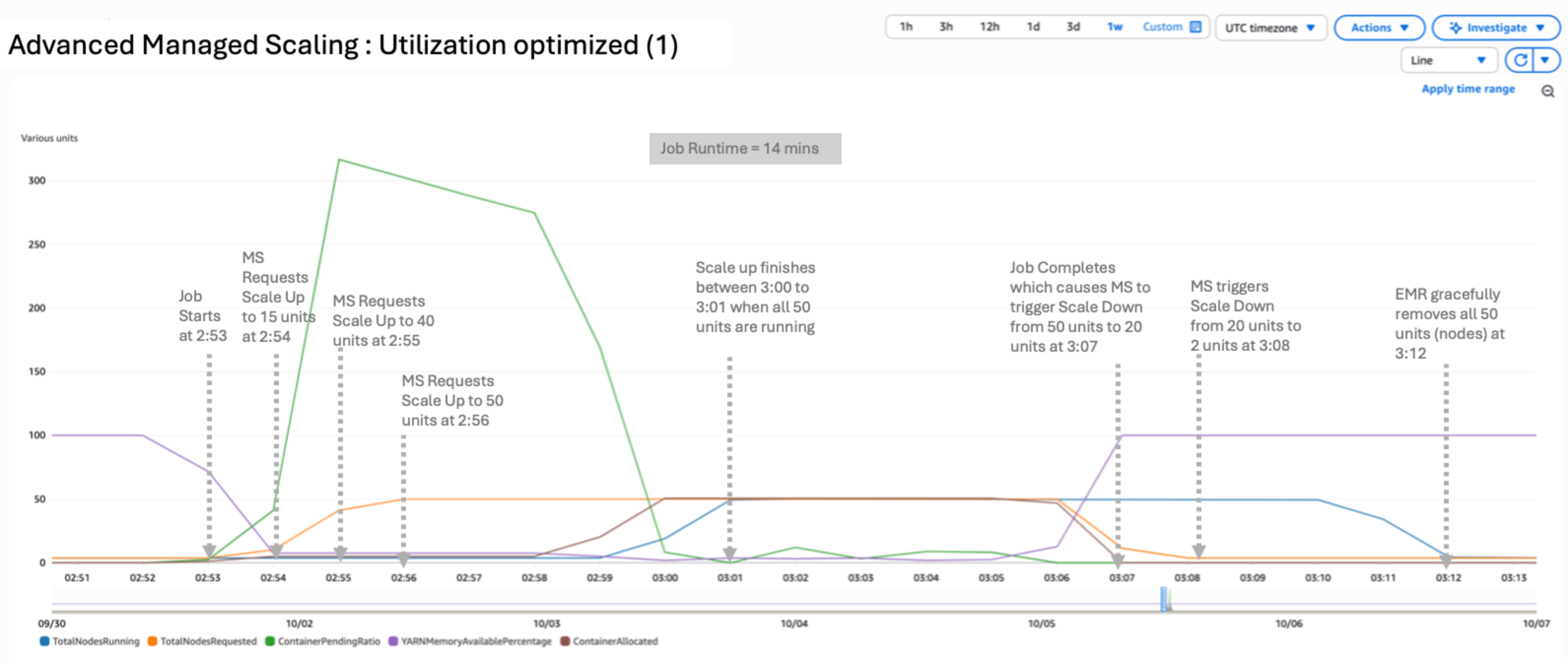
State of affairs 1: Utilization optimized
On this state of affairs, we used a utilization optimized configuration by setting UtilizationPerformanceIndex to 1:
The results of the take a look at yielded a peak of 16 nodes working and 16 requested. The size-up and scale-down course of is conservative. It takes quarter-hour to utterly launch the nodes after the requested metric subsides, as proven within the following determine. The job accomplished in 12 minutes, 39 seconds. UtilizationPerformanceIndex of 1 or 25 may be helpful when the cluster is working a sequence of jobs with little to zero idle time. It may stop frequent node churn as a result of nodes can be accessible for the subsequent set of jobs.
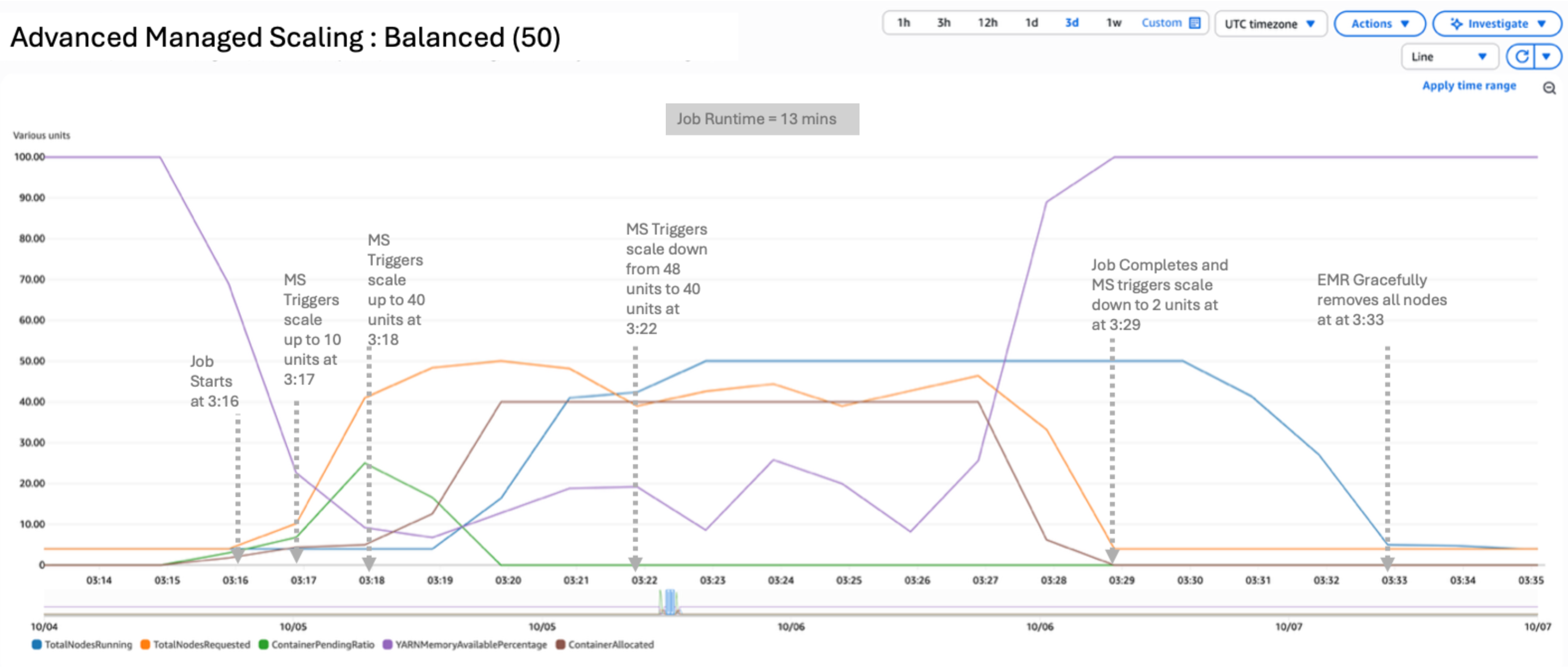
State of affairs 2: Balanced
On this state of affairs, we used a balanced configuration by setting UtilizationPerformanceIndex to 50:
The results of the take a look at yielded a peak of 43 nodes working and 32 requested. UtilizationPerformanceIndex of fifty makes use of a balanced strategy for scaling the assets. Nodes requested and working are increased such which you could get a greater price-performance ratio. The job accomplished in 7 minutes, 1 second.
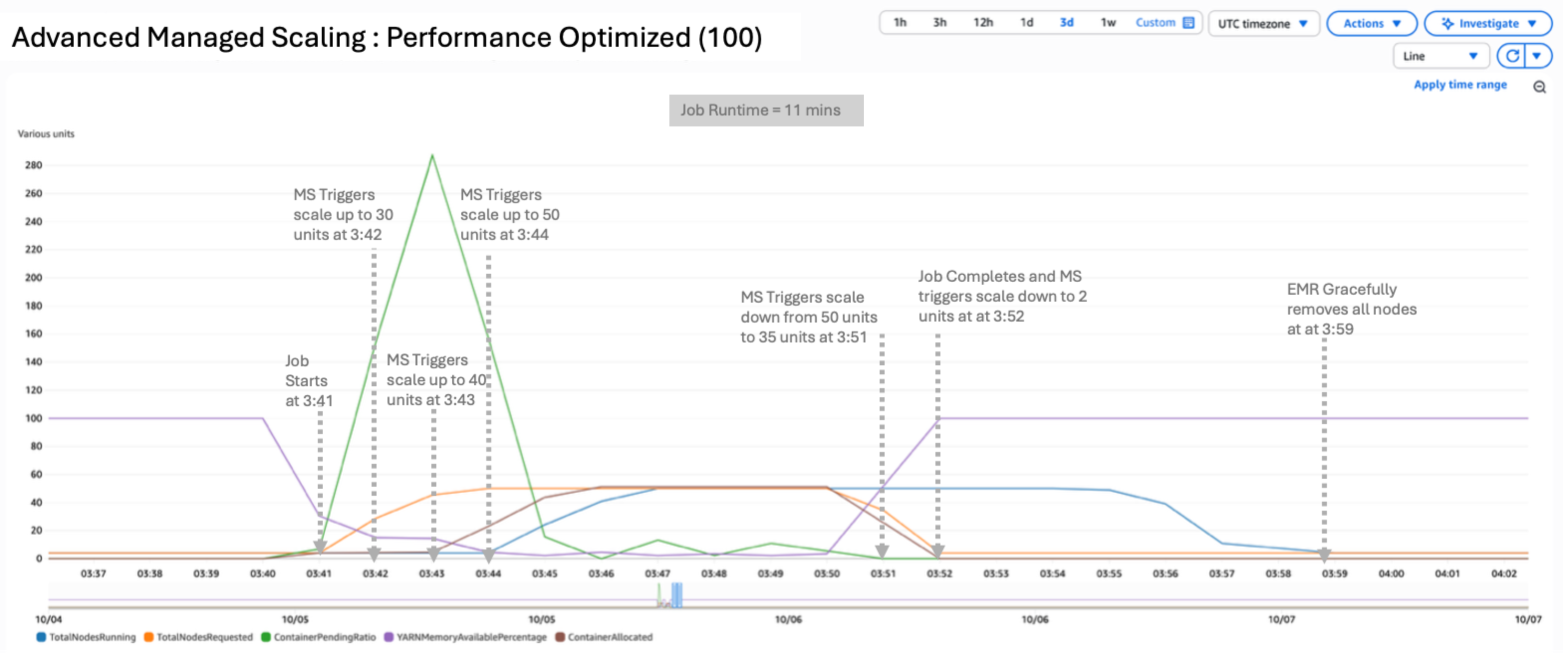
State of affairs 3: Efficiency optimized
On this state of affairs, we used a efficiency optimized configuration by setting UtilizationPerformanceIndex to 100:
The results of the take a look at yielded a peak of fifty nodes working and 46 requested. UtilizationPerformanceIndex of 100 delivers the very best efficiency by aggressively scaling assets up and down. You may anticipate the very best nodes requested and working on this configuration. Scale-down will intently comply with the node requested metric and due to this fact can result in frequent churn of nodes if there are brief idle durations between job submissions. This setting is right for latency-sensitive workloads that want to complete underneath SLA. The instance job accomplished in 6 minutes, 16 seconds.
Comparability
The next desk summarizes the variations between these scaling strategies and time taken for every.
| Scaling Technique | Utilization Index | Peak Complete Nodes Requested | Peak Complete Nodes Operating | Job Run Time (Seconds) | Value to Run job | Use Case |
| Scenario1 – Utilization optimized | 1 | 16 | 16 | 759 | Low | Workloads with common spikes; prioritizes value effectivity with conservative scaling |
| State of affairs 2 – Balanced | 50 | 32 | 43 | 421 | Medium | Regular workloads with combined stage durations; really helpful place to begin |
| State of affairs 3 – Efficiency Optimized | 100 | 46 | 50 | 376 | Excessive | SLA-sensitive workloads requiring quick completion occasions |
Superior Managed Scaling in Amazon EMR introduces a extra nuanced strategy to cluster administration by the custom-made scaling methods to fulfill your corporation necessities. This spectrum provides fine-grained management over how clusters reply to workload calls for. At one finish, with a utilization optimized configuration of 1, the system prioritizes environment friendly useful resource utilization, scaling up conservatively to take care of cost-effectiveness and making the most of present cluster assets. Within the balanced configuration at 50, the technique goals to strike an equilibrium between useful resource utilization and job efficiency. To fulfill efficiency SLAs, the efficiency optimized worth of 100 confirmed aggressive scaling responding to elevated demand for assets rapidly, no matter useful resource consumption. This granular management helps you fine-tune your cluster’s habits based mostly in your particular wants, balancing value, effectivity, and efficiency.
Conclusion
To Summarize, Superior Scaling for Amazon EMR represents an development in cluster administration, providing better management and effectivity. By fine-tuning your clusters’ habits, you’ll be able to obtain cheaper and performant large information processing. We encourage you to do that new function and uncover the way it can optimize your EMR workloads. Begin by experimenting with totally different UtilizationPerformanceIndex values and intently monitor your cluster’s efficiency and value metrics. Over time, it is possible for you to to search out the right stability that meets your particular wants.
To study extra about Amazon EMR Managed Scaling and Superior Scaling, confer with our documentation. We’re excited to see how you utilize this new functionality to boost your large information processing on AWS, and we sit up for your suggestions as we proceed to evolve and enhance our companies.
Concerning the authors