
In case you’ve ever watched a recreation and puzzled, “How do manufacturers truly measure how typically their emblem exhibits up on display screen?” you’re already asking an ACR query. Equally, insights like:
- What number of minutes did Model X’s emblem seem on the jersey?
- Did that new sponsor truly get the publicity they paid for?
- Is my emblem being utilized in locations it shouldn’t be?
are all powered by Automated Content material Recognition (ACR) know-how. It appears to be like at uncooked audio/video and figures out what’s in it with out counting on filenames, tags, or human labels.
On this publish, we’ll zoom into one very sensible slice of ACR: Recognizing model logos in photos or video utilizing a totally open-source stack.
Introduction to Automated Content material Recognition
Automated Content material Recognition (ACR) is a media recognition know-how (much like facial recognition know-how) able to recognizing the contents in media with out human intervention. Whether or not you could have witnessed an app in your Smartphone figuring out the track that’s being performed, or a streaming platform labeling actors in a scene, you could have been experiencing the work of ACR. Units utilizing ACR seize a “fingerprint” of audio or video and evaluate it to a database of content material. When a match is discovered, the system returns metadata about that content material, for instance, the identify of a track or the id of an actor on display screen nevertheless it will also be used to acknowledge logos and model marks in photos or video. This text will illustrate the way to construct an ACR system targeted on recognizing logos in a picture or video.
We are going to stroll by a step-by-step emblem recognition pipeline that assumes a metric-learning embedding mannequin (e.g., a CNN/ViT educated with contrastive/triplet, or ArcFace-style loss) to provide ℓ2-normalized vectors for emblem crops and use Euclidean distance (L2 norm) to match new photos towards a gallery of brand name logos. The goal is to point out how a gallery of emblem exemplars (imaginary logos created for this text) can be utilized as our reference database and the way we will routinely decide which emblem seems in a brand new picture by finding the closest match in our embedding area.
As soon as the system is constructed, we’ll measure the system accuracy and touch upon the method of choosing the suitable distance threshold for use in efficient recognition. On the finish of it, you should have an concept of the weather of a emblem recognition ACR pipeline and be able to testing your dataset of emblem photos or some other use case.
Why Emblem ACR Is a Massive Deal?
Logos are the visible shorthand for manufacturers. In case you can detect them reliably, you unlock a complete set of high-value use instances:
- Sponsorship & advert verification: Did the brand seem when and the place the contract promised? How lengthy was it seen? On which channels?
- Model security & compliance: Is your emblem displaying up subsequent to content material you don’t wish to be related to? Are opponents ambushing your marketing campaign?
- Shoppable & interactive experiences: See a emblem on display screen → faucet your cellphone or distant → see merchandise, presents, or coupons in actual time.
- Content material search & discovery: “Present me all clips the place Model A, Model B, and the brand new stadium sponsor seem collectively.”
On the core of all these situations is similar query:
Given a body from a video, which emblem(s) are in it, if any?
That’s precisely what we’ll design.
The Massive Thought: From Pixels to Vectors to Matches
Trendy ACR is mainly a three-step magic trick:
- Have a look at the sign – Seize frames from the video stream.
- Flip photos into vectors – Use a deep mannequin to map every emblem crop to a compact numerical vector (an embedding).
- Search in vector area – Evaluate that vector to a gallery of recognized emblem vectors utilizing a vector database or ANN library.
If a brand new emblem crop lands shut sufficient to a cluster of “Model X” vectors, we name it a match. That’s it. Every part else, detectors, thresholds, and indexing, are simply making this sooner, extra sturdy, and extra scalable.
Emblem Dataset
To construct our Emblem recognition ACR system, we’d like a reference dataset of Logos with recognized identities. We are going to use a group of Log photos created artificially utilizing AI for this case research. Despite the fact that we’re utilizing some random imaginary logos for this text, this may be prolonged even to downloading recognized logos if in case you have the license to make use of them or an current analysis dataset. In our case, we’ll work with a small pattern: for instance, a dozen manufacturers with 5 to 10 photos per model.
The model identify of the brand is offered as a label of every emblem within the dataset, and it’s the ground-truth id.
These logos present variability that issues for recognition, for instance, in colorways (full-color, black/white, inverted), structure (horizontal vs. stacked), wordmark vs. icon-only, background/define remedies, and, within the wild, they seem below completely different scales, rotations, blur, occlusions, lighting, and views. The system needs to be primarily based on the similarities within the emblem, as it would seem very completely different in conditions. We suppose that we now have cropped emblem photos in order that our recognition mannequin truly takes as enter solely the brand area.
Illustration within the ACR System
For instance, take into account that we now have in our database logos of recognized logos as Photograph A, Photograph B, Photograph C, and so forth. (every of them is an imaginary emblem generated utilizing AI). Every of those logos will probably be represented as a numerical encoding within the ACR system and saved.
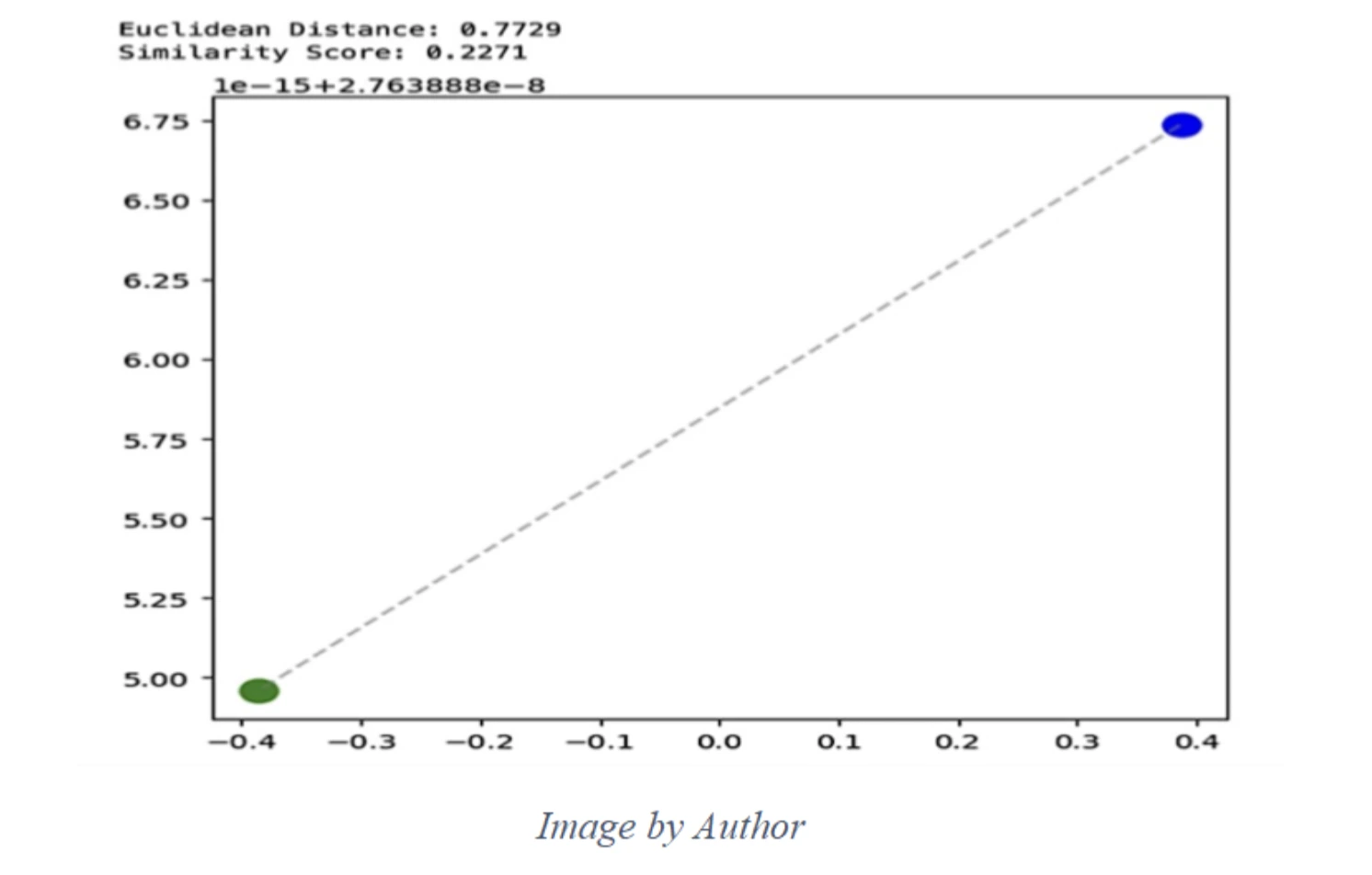
Under, we present an instance of 1 imaginary model emblem in two completely different photos from our dataset:


{kind=link}
We are going to use a pre-trained mannequin to detect the Emblem in two photos of the above identical model.
This determine is displaying two factors (inexperienced and blue), the straight-line (Euclidean) distance between them, after which a “similarity rating” that’s only a easy remodel of that distance.
An Open-Supply Stack for Emblem ACR
In follow, many groups right this moment use light-weight detectors similar to YOLOv8-Nano and backbones like EfficientNet or Imaginative and prescient Transformers, all obtainable as open-source implementations.
Core elements
- Deep studying framework: PyTorch or TensorFlow/Keras; used to coach and run the brand embedding mannequin.
- Emblem detector: Any open-source object detector (YOLO-style, SSD, RetinaNet, and so forth.) educated to seek out “logo-like” areas in a body.
- Embedding mannequin: A CNN or Imaginative and prescient Transformer spine (ResNet, EfficientNet, ViT, …) with a metric-learning head that outputs unit-normalized vectors.
- Vector search engine: FAISS library, or a vector DB like Milvus / Qdrant / Weaviate to retailer tens of millions of embeddings and reply “nearest neighbor” queries shortly.
- Emblem knowledge: Artificial or in-house emblem photos, plus any public datasets that explicitly enable your meant use.
You may swap any part so long as it performs the identical function within the pipeline.
Step 1: Discovering Logos within the Wild
Earlier than we will acknowledge a emblem, we now have to seek out it.
1. Pattern frames
Processing each single body in a 60 FPS stream is overkill. As an alternative:
- Pattern 2 to 4 frames per second per stream.
- Deal with every sampled body as a nonetheless picture to examine.
That is often sufficient for model/sponsor analytics with out breaking the compute funds.
2. Run a emblem detector
On every sampled body:
- Resize and normalize the picture (commonplace pre-processing).
- Feed it into your object detector.
- Get again bounding containers for areas that appear like logos.
Every detection is:
(x_min, y_min, x_max, y_max, confidence_score)
You crop these areas out; every crop is a “emblem candidate.”
3. Stabilize over time
Actual-world video is messy: blur, movement, partial occlusion, a number of overlays.
Two straightforward tips assist:
- Temporal smoothing – mix detections throughout a brief window (e.g., 1–2 seconds). If a emblem seems in 5 consecutive frames and disappears in a single, don’t panic.
- Confidence thresholds – discard detections under a minimal confidence to keep away from apparent noise.
After this step, you could have a stream of fairly clear emblem crops.
Step 2: Emblem Embeddings
Now that we will crop logos from frames, we’d like a strategy to evaluate them that’s smarter than uncooked pixels. That’s the place embeddings are available.
An embedding is only a vector of numbers (for instance, 256 or 512 values) that captures the “essence” of a emblem. We prepare a deep neural community in order that:
- Two photos of the identical emblem map to vectors which might be shut collectively.
- Pictures of various logos map to vectors which might be far aside.
A standard strategy to prepare that is with a metric-learning loss similar to ArcFace. You don’t want to recollect the system; the instinct is:
“Pull embeddings of the identical model collectively within the embedding area, and push embeddings of various manufacturers aside.”
After coaching, the community behaves like a black field:
Under: Scatter plot displaying a 2D projection of emblem embeddings for 3 recognized manufacturers/logos (A, B, C). Every level is one emblem picture, which is embedded from the identical model cluster tightly, displaying clear separation between manufacturers within the embedding area.
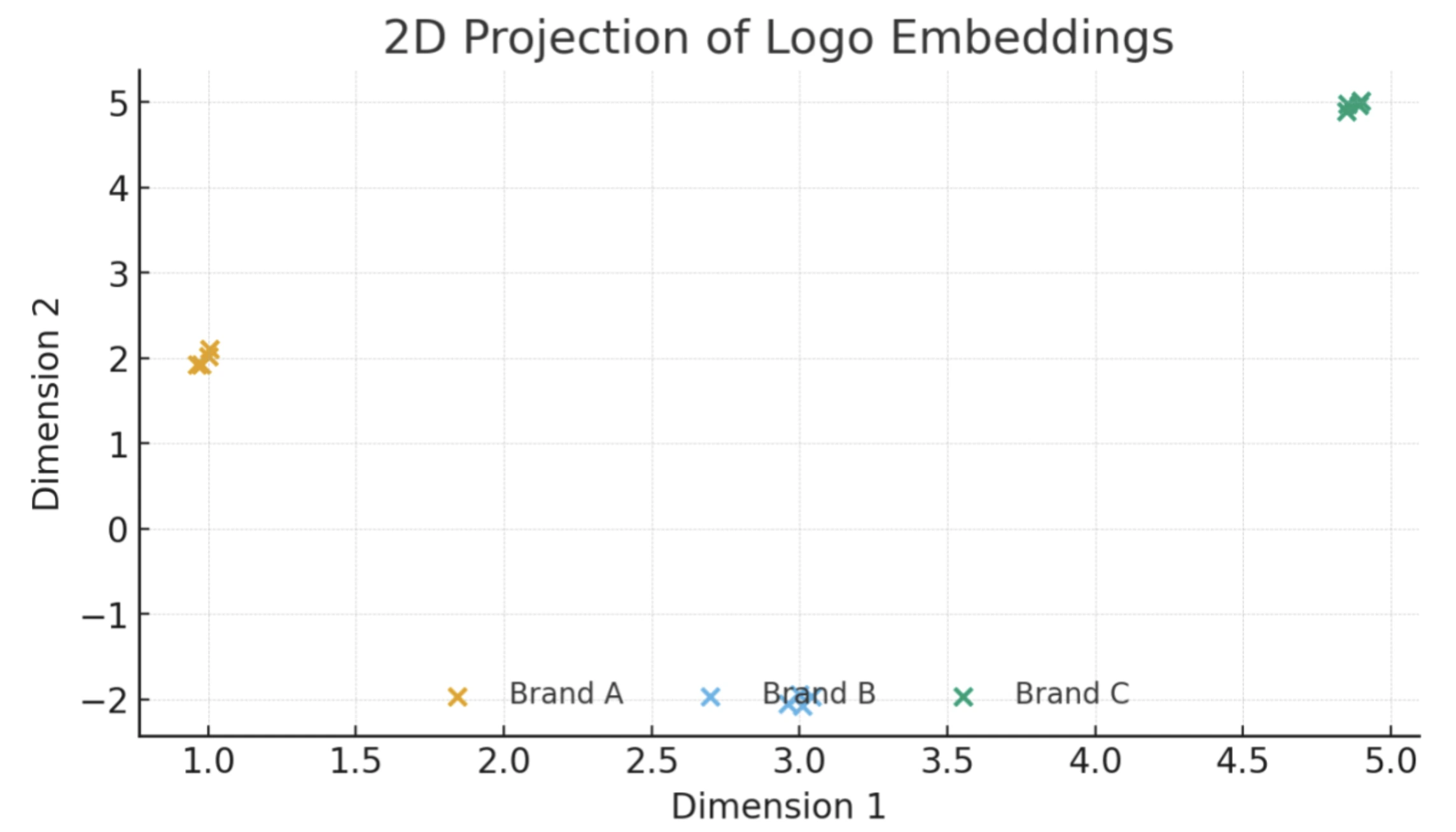
We are able to use a emblem embedding mannequin educated with the ArcFace-style (additive angular margin) loss to provide ℓ2-normalized 512-D vectors for every emblem crop. There are lots of open-source methods to construct a emblem embedder. The best manner is to load a normal imaginative and prescient spine (e.g., ResNet/EfficientNet/ViT) with an ArcFace-style (additive angular margin) head.
Let’s have a look at how this works in code-like type. We’ll assume:
- embedding_model(picture) takes a emblem crop and returns a unit-normalized embedding vector.
- detect_logos(body) returns an inventory of emblem crops for every body.
- l2_distance(a, b) computes the Euclidean distance between two embeddings.
First, we construct a small embedding database for our recognized manufacturers:
embedding_model = load_embedding_model("arcface_logo_model.pt") # PyTorch / TF mannequin
brand_db = {} # dict: brand_name -> record of embedding vectors
for brand_name in brands_list:
examples = []
for img_path in logo_images[brand_name]: # paths to instance photos for this model
img = load_image(img_path)
crop = preprocess(img) # resize / normalize
emb = embedding_model(crop) # unit-normalized emblem embedding
examples.append(emb)
brand_db[brand_name] = examplesAt runtime, we acknowledge logos in a brand new body like this:
def recognize_logos_in_frame(body, threshold):
crops = detect_logos(body) # emblem detector returns candidate crops
outcomes = []
for crop in crops:
query_emb = embedding_model(crop)
best_brand = None
best_dist = float("inf")
# discover the closest model within the database
for brand_name, emb_list in brand_db.gadgets():
# distance to the closest instance for this model
dist_to_brand = min(l2_distance(query_emb, e) for e in emb_list)
if dist_to_brand < best_dist:
best_dist = dist_to_brand
best_brand = brand_name
if best_dist < threshold:
outcomes.append({
"model": best_brand,
"distance": best_dist,
# you'll additionally embody bounding field from the detector
})
else:
outcomes.append({
"model": None, # unknown / not in catalog
"distance": best_dist,
})
return outcomesIn an actual system, you wouldn’t loop over each embedding in Python. You’d drop the identical concept right into a vector index similar to FAISS, Milvus, or Qdrant, that are open-source engines designed to deal with nearest-neighbor search over tens of millions of embeddings effectively. However the core logic is strictly what this pseudocode exhibits:
- Embed the question emblem,
- Discover the closest recognized emblem within the database,
- Verify if the gap is under a threshold to determine if it’s a match.
Euclidean Distance for Emblem Matching
We are able to now categorical logos as numerical vectors, however how will we evaluate them? Embeddings have a couple of frequent similarity measures, and Euclidean distance and cosine similarity are probably the most used. As a result of our emblem embeddings are ℓ2-normalized (ArcFace-style), cosine similarity and Euclidean distance give the identical rating (one may be derived from the opposite). Our distance measure will probably be Euclidean distance (L2 norm).
Euclidean distance between two function vectors (x) and (y) (every of size (d), right here (d = 512)) is outlined as: distance=√(Σ(xi−yi)²)
After the sq. root, that is the straight-line distance between the 2 factors in 512-D area. A smaller distance means the factors are nearer, which—by how we educated the mannequin—signifies the logos usually tend to be the identical model. If the gap is massive, they’re completely different manufacturers. Utilizing Euclidean distance on the embeddings turns matching right into a nearest-neighbor search in function area. It’s successfully a Ok-Nearest Neighbors method with Ok=1 (discover the one closest match) plus a threshold to determine if that match is assured sufficient.
Nearest-Neighbor Matching
Utilizing Euclidean distance as our similarity measure is simple to implement. We calculate the gap between a question emblem’s embedding and every saved model embedding in our database, then take the minimal. The model comparable to that minimal distance is our greatest match. This methodology finds the closest neighbor in embedding area—if that nearest neighbor remains to be pretty far (distance bigger than a threshold), we conclude the question emblem is “unknown” (i.e., not one in every of our recognized manufacturers). The edge is essential to keep away from false positives and needs to be tuned on validation knowledge.
To summarize, Euclidean distance in our context means: the nearer (in Euclidean distance) a question embedding is to a saved embedding, the extra related the logos, and therefore the extra probably the identical model. We are going to use this precept for matching.
Step-by-Step Mannequin Pipeline (Emblem ACR)
Let’s break down the whole pipeline of our emblem detection ACR system into clear steps:
1. Knowledge Preparation
Gather photos of recognized manufacturers’ logos (official art work + “in-the-wild” photographs). Manage by model (folder per model or (model, image_path) record). For in-scene photos, run a emblem detector to crop every emblem area; apply mild normalization (resize, padding/letterbox, non-compulsory distinction/perspective repair).
2. Embedding Database Creation
Use a emblem embedder (ArcFace-style/additive-angular-margin head on a imaginative and prescient spine) to compute a 256–512D vector for each emblem crop. Retailer as a mapping model → [embeddings] (e.g., a Python dict or a vector index with metadata).
3. Normalization
Guarantee all embeddings are ℓ2-normalized (unit size). Many fashions output unit vectors; if not, normalize so distance comparisons are constant.
4. New Picture / Stream Question
For every incoming picture/body, run the brand detector to get candidate containers. For every field, crop and preprocess precisely as in coaching, then compute the brand embedding.
5. Distance Calculation
Evaluate the question embedding to the saved catalog utilizing Euclidean (L2) or cosine (equal for unit vectors). For big catalogs or real-time streams, use an ANN index (e.g., FAISS HNSW/IVF) as a substitute of brute drive.
6. Discover Nearest Match
Take the closest neighbor in embedding area. In case you maintain a number of exemplars per model, use the very best rating per model (max cosine / min L2) and decide the highest model.
7. Threshold Verify (Open-set)
Evaluate the very best rating to a tuned threshold.
- Rating passes → acknowledge the brand as that model.
- Rating fails → unknown (not in catalog). Thresholds are calibrated on validation pairs to steadiness false positives vs. misses; optionally apply temporal smoothing throughout frames.
8. Output Outcome
Return model id, bounding field, and similarity/distance. If unknown, deal with per coverage (e.g., “No match in catalog” or route for overview). Optionally log matches for auditing and mannequin enchancment.
Visualizing Similarity and Matching
The similarity scores (or distances) are sometimes useful to visualise the best way the system is making choices. For instance, supplied with a question picture, we will look at the calculated distance to each candidate within the database. Ideally, the suitable id will probably be far lower than others and can set up a definite separation between the closest one and the remaining.
The chart under illustrates an instance. We had a question picture of Emblem C, and we computed its Euclidean distance to the embeddings of 5 candidate Logos (LogoA by LogoE) in our database. We then plotted these distances:

On this instance, the clear separation between the real match (LogoC) and the others makes it straightforward to decide on a threshold. In follow, distances will range relying on the pair of photos. Two Logos of the identical model would possibly generally yield a distance barely greater, particularly if the Logos are very completely different, and two completely different model Logos can often have a surprisingly low distance if they appear alike. That’s why threshold tuning is required utilizing a validation set.
Accuracy and Threshold Tuning
To measure system accuracy, we might run the system on a take a look at set of emblem photos (the place there may be recognized id, however not within the database) and depend the variety of instances the system identifies the manufacturers appropriately. We might range the gap threshold and observe the trade-off between false positives, or the detection of a recognized emblem of a model as one other one, and false negatives, or the failure to detect a recognized emblem as a result of the gap is bigger than the brink. As a way to decide a very good worth, a plot of the ROC curve or just a calculation of precision/recall at completely different thresholds may be related.
How you can tune the brink (easy, repeatable):
- Construct pairs.
– Real pairs: embeddings from the identical model (completely different information/angles/colours).
– Impostor pairs: embeddings from completely different manufacturers (embody look-alike marks, color-inverted variations). - Rating pairs. Compute Euclidean (L2) or cosine (on unit vectors, they rank identically).
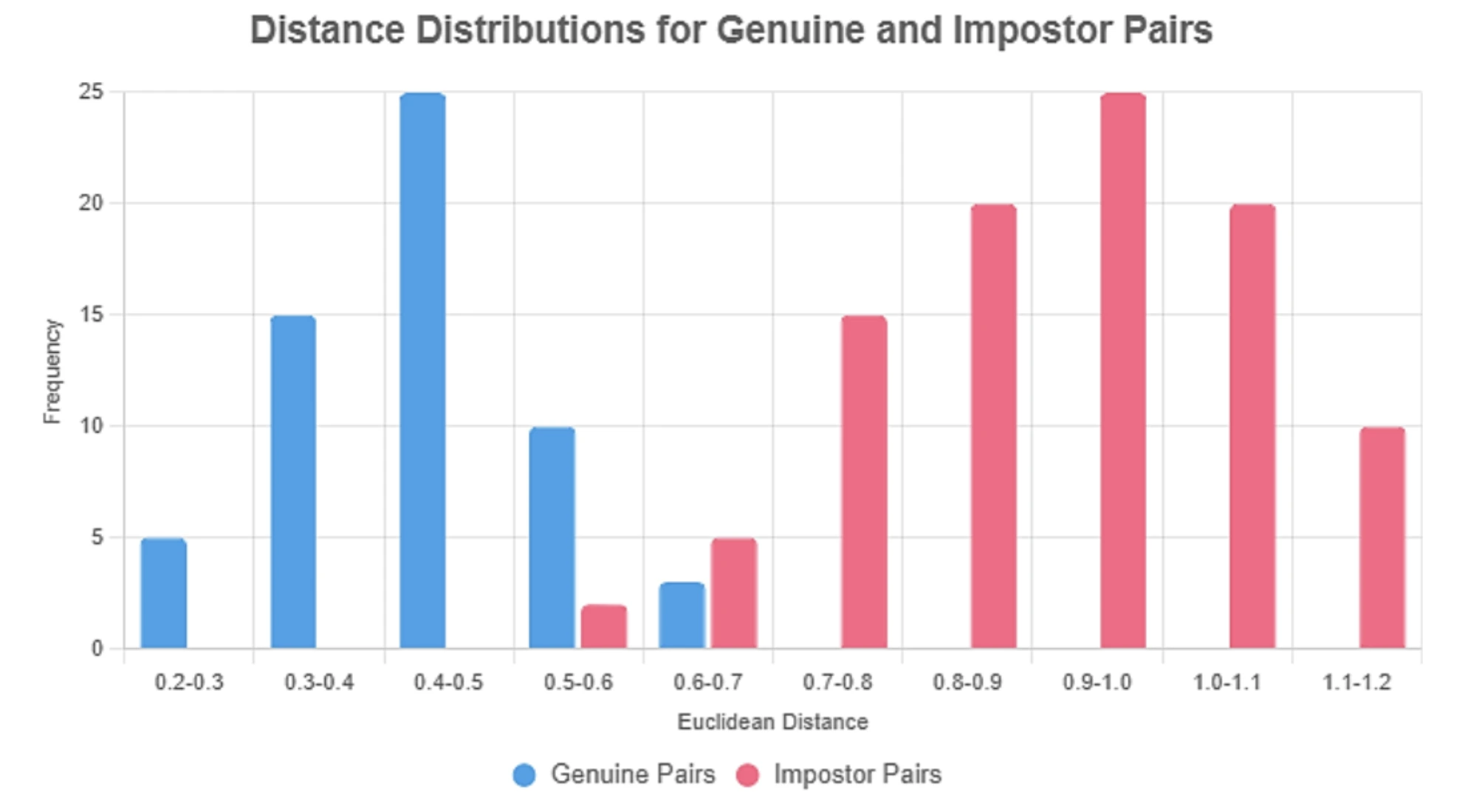
- Plot histograms. It’s best to see two distributions: same-brand distances clustered low and different-brand distances greater.
- Select a threshold. Decide the worth that greatest separates the 2 distributions on your goal threat (e.g., the gap the place FAR = 1%, or the argmax of F1).
- Open set verify. Add non-logo crops and unknown manufacturers to your negatives; confirm the brink nonetheless controls false accepts
Under: Histogram of Euclidean distances for same-brand (real) vs different-brand (impostor) emblem pairs. The dashed line exhibits the chosen threshold separating most real from impostor matches.
In abstract, to attain good accuracy:
- Use a number of logos per model if attainable, when constructing the database, or use augmentation, so the mannequin has a greater probability of getting a consultant embedding
- Consider distances on recognized validation pairs to grasp the vary of same-brand vs different-brand distances.
- Set the brink to steadiness missed recognitions vs false alarms primarily based on these distributions. You can begin with generally used values (like 0.6 for 128-D embeddings or round 1.24 for 512-D threshold), then regulate.
- High quality-tune as wanted: If the system is making errors, analyze them. Are the false positives coming from particular look-alike logos? Are the false negatives coming from low-quality photos? This evaluation can information changes (perhaps a decrease threshold, or including extra reference photos for sure logos, and so forth.).
Conclusion
On this article, we constructed a simplified Automated Content material Recognition system for figuring out model logos in photos utilizing deep emblem embeddings and Euclidean distance. We launched ACR and its use instances, assembled an open-licensed emblem dataset, and used an ArcFace-style embedding mannequin (for logos) to transform cropped logos right into a numerical illustration. By evaluating these embeddings with a Euclidean distance measure, the system can routinely acknowledge a brand new emblem by discovering the closest match in a database of recognized manufacturers. We demonstrated how the pipeline works with code snippets and visualized how a choice threshold may be utilized to enhance accuracy.
Outcomes: With a well-trained emblem embedding mannequin, even a easy nearest-neighbor method can obtain excessive accuracy. The system appropriately identifies recognized manufacturers in question photos when their embeddings fall inside an acceptable distance threshold of the saved templates. We emphasised the significance of threshold tuning to steadiness precision and recall, a vital step in real-world deployments.
Subsequent Steps
There are a number of methods to increase or enhance this ACR system:
- Scaling Up: To assist hundreds of manufacturers or real-time streams, substitute brute-force distance checks with an environment friendly similarity index (e.g., FAISS or different approximate nearest neighbor strategies)
- Detection & Alignment: Carry out emblem detection with a quick detector (e.g., YOLOv8-Nano/EfficientDet-Lite/SSD) and apply mild normalization (resize, padding, non-compulsory perspective/distinction fixes) so the embedder sees constant crops.
- Bettering Accuracy: High quality-tune the embedder in your emblem set and add tougher augmentations (rotation, scale, occlusion, shade inversion). Preserve a number of exemplars per model (shade/mono/legacy marks) or use prototype averaging..
- ACR Past Logos: The identical embedding + nearest-neighbor method extends to product packaging, ad-creative matching, icons, and scene textual content snippets.
- Authorized & Ethics: Respect trademark/IP, dataset licenses, and picture rights. Use solely belongings with permission on your function (together with industrial use). If photos embody folks, adjust to privateness/biometric legal guidelines; monitor regional/model protection to cut back bias.
Automated Content material Recognition is a strong deep studying know-how that powers most of the units and companies we use each day. By understanding and constructing a easy system for detection & recognition with Euclidean distance, we achieve perception into how machines can “see” and determine content material. From indexing logos or movies to enhancing viewer experiences, the probabilities of ACR are huge, and the method outlined here’s a basis that may be tailored to many thrilling functions.
Sherin Sunny is a Senior Engineering Supervisor at Walmart Vizio, the place he leads the core engineering group accountable for large-scale Automated Content material Recognition (ACR) in AWS Cloud. His work spans cloud migrations, AI ML pushed clever pipelines, vector search techniques, and real-time knowledge platforms that energy next-generation content material analytics
Login to proceed studying and revel in expert-curated content material.