

{kind=link}
Spatial knowledge processing and evaluation is enterprise important for geospatial workloads on Databricks. Many groups depend on exterior libraries or Spark extensions like Apache Sedona, Geopandas, Databricks Lab venture Mosaic, to deal with these workloads. Whereas prospects have been profitable, these approaches add operational overhead and infrequently require tuning to achieve acceptable efficiency.
Early this 12 months, Databricks launched help for Spatial SQL, which now consists of 90 spatial capabilities, and help for storing knowledge in GEOMETRY or GEOGRAPHY columns. Databricks built-in Spatial SQL is the most effective strategy for storing and processing vector knowledge in comparison with any various as a result of it addresses the entire main challenges of utilizing add-on libraries: extremely steady, blazing efficiency, and with Databricks SQL Serverless, no must handle traditional clusters, library compatibility, and runtime variations.
Some of the widespread spatial processing duties is to match whether or not two geometries overlap, the place one geometry comprises the opposite, or how shut they’re to one another. This evaluation requires using spatial joins, for which nice out-of-the-box efficiency is crucial to speed up time to spatial perception.
Spatial joins as much as 17x quicker with Databricks SQL Serverless
We’re excited to announce that each buyer utilizing built-in Spatial SQL for spatial joins, will see as much as 17x quicker efficiency in comparison with traditional clusters with Apache Sedona1 put in. The efficiency enhancements can be found to all prospects utilizing Databricks SQL Serverless and Basic clusters with Databricks Runtime (DBR) 17.3. If you happen to’re already utilizing Databricks built-in spatial predicates, like ST_Intersects or ST_Contains, no code change required.
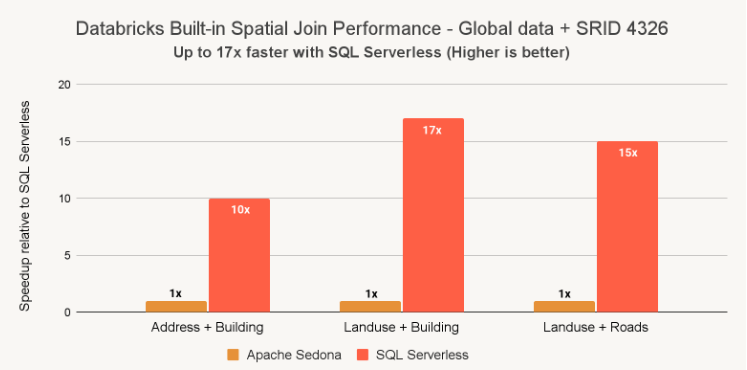
Apache Sedona 1.7 was not suitable with DBR 17.x on the time of the benchmarks, DBR 16.4 was used.
Working spatial joins presents distinctive challenges, with efficiency influenced by a number of components. Geospatial datasets are sometimes extremely skewed, like with dense city areas and sparse rural areas, and fluctuate extensively in geometric complexity, such because the intricate Norwegian shoreline in comparison with Colorado’s easy borders. Even after environment friendly file pruning, the remaining be part of candidates nonetheless demand compute-intensive geometric operations. That is the place Databricks shines.
The spatial be part of enchancment comes from utilizing R-tree indexing, optimized spatial joins in Photon, and clever vary be part of optimization, all utilized mechanically. You write customary SQL with spatial capabilities, and the engine handles the complexity.
The enterprise significance of spatial joins
A spatial be part of is much like a database be part of however as an alternative of matching IDs, it makes use of a spatial predicate to match knowledge primarily based on location. Spatial predicates consider the relative bodily relationship, resembling overlap, containment, or proximity, to attach two datasets. Spatial joins are a robust device for spatial aggregation, serving to analysts uncover tendencies, patterns, and location-based insights throughout totally different locations, from procuring facilities and farms, to cities and your complete planet.
Spatial joins reply business-critical questions throughout each business. For instance:
- Coastal authorities monitor vessel site visitors inside a port or nautical boundaries
- Retailers analyze car site visitors and visitation patterns throughout retailer areas
- Fashionable agriculture firms carry out crop yield evaluation and forecasting by combining climate, discipline, and seed knowledge
- Public security companies and insurance coverage firms find which houses are at-risk from flooding or hearth
- Vitality and utilities operations groups construct service and infrastructure plans primarily based on evaluation of power sources, residential and business land use, and current property
Spatial be part of benchmark prep
For the info, we chosen 4 worldwide large-scale datasets from Overture Maps Basis: Addresses, Buildings, Landuse, and Roads. You possibly can check the queries your self utilizing the strategies described beneath.
We used Overture Maps datasets, which have been initially downloaded as GeoParquet. An instance of making ready addresses for the Sedona benchmarking is proven beneath. All datasets adopted the identical sample.
We additionally processed the info into Lakehouse tables, changing the parquet WKB into native GEOMETRY knowledge sorts for Databricks benchmarking.
Comparability queries
The chart above makes use of the identical set of three queries, examined towards every compute.
Question #1 – ST_Contains(buildings, addresses)
This question evaluates the two.5B constructing polygons that comprise the 450M deal with factors (point-in-polygon be part of). The result’s 200M+ matches. For Sedona, we reversed this to ST_Within(a.geom, b.geom) to help default left build-side optimization. On Databricks, there isn’t a materials distinction between utilizing ST_Contains or ST_Within.
Question #2 – ST_Covers(landuse, buildings)
This question evaluates the 1.3M worldwide `industrial` landuse polygons that cowl the two.5B constructing polygons. The result’s 25M+ matches.
Question #3 – ST_Intersects(roads, landuse)
This question evaluates the 300M roads that intersect with the 10M worldwide ‘residential’ landuse polygons. The result’s 100M+ matches. For Sedona, we reversed this to ST_Intersects(l.geom, trans.geom) to help default left build-side optimization.
What’s subsequent for Spatial SQL and native sorts
Databricks continues so as to add new spatial expressions primarily based on buyer requests. Here’s a checklist of spatial capabilities that have been added since Public Preview: ST_AsEWKB, ST_Dump, ST_ExteriorRing, ST_InteriorRingN, ST_NumInteriorRings. Accessible now in DBR 18.0 Beta: ST_Azimuth, ST_Boundary, ST_ClosestPoint, help for ingesting EWKT, together with two new expressions, ST_GeogFromEWKT and ST_GeomFromEWKT, and efficiency and robustness enhancements for ST_IsValid, ST_MakeLine, and ST_MakePolygon.
Present your suggestions to the Product workforce
If you need to share your requests for added ST expressions or geospatial options, please fill out this quick survey.
Replace: Open sourcing geo sorts in Apache Spark™
The contribution of GEOMETRY and GEOGRAPHY knowledge sorts to Apache Spark™ has made nice progress and is on observe to be dedicated to Spark 4.2 in 2026.
Strive Spatial SQL out free of charge
Run your subsequent Spatial question on Databricks SQL at this time – and see how briskly your spatial joins will be. To be taught extra about Spatial SQL capabilities, see the SQL and Pyspark documentation. For extra data on Databricks SQL, try the web site, product tour, and Databricks Free Version. If you wish to migrate your current warehouse to a high-performance, serverless knowledge warehouse with an awesome consumer expertise and decrease whole value, then Databricks SQL is the answer — strive it free of charge.